
亚太地区正在成为全球AI应用最活跃的区域之一,但其领先优势更多体现在“使用广度”,而非“价值深度”。调研显示,78%的受访者已成为AI高频用户,显著高于全球平均水平。其中,一线员工使用率达到78%,较全球高出19个百分点,反映出AI在基层岗位的快速渗透。分市场看,印度、印尼与中国的使用率均超过87%,构成区域内最强增长极。这一结构意味着,AI正在从管理工具转变为普遍生产力基础设施。 从应用层面看,当前AI价值主要集中在效率提升而非业务重构。58%的用户将AI用于行政事务,56%用于写作任务,48%用于创意工作,这些高度标准化场景成为最先被自动化替代的领域。进一步来看,46%的员工每天可节省超过1小时工作时间,而这些时间中,40%被用于提升工作质量,39%转向更具战略性的任务。这表明AI正在释放认知资源,但仍停留在“局部优化”的阶段,尚未形成系统性生产力跃迁。 尽管应用广泛,亚太企业在价值转化上仍显滞后。全球领先企业将70%的AI预算投入流程重构与业务创新,而亚太企业仅为57%,更多资源仍集中在单点工具部署。这种结构导致AI收益集中于个体效率,而非组织级变革。换言之,亚太企业已实现“高使用率”,但尚未完成“高转型率”,若缺乏端到端流程再设计,技术红利将逐步触及天花板。 员工情绪呈现出典型的“双峰结构”。一方面,区域整体乐观情绪达到60%,较全球高出8个百分点,年轻群体与新兴经济体尤为明显;另一方面,52%的员工担忧未来十年可能失业,高于全球11个百分点。在中国,这一比例甚至达到71%。这种“既拥抱又恐惧”的心理状态,反映出AI既是效率工具,也是结构性替代力量,正在重塑劳动力市场预期。 组织治理的滞后正在放大这一矛盾。仅31%的一线员工感受到明确的领导支持,但在获得支持的群体中,AI使用率提升31个百分点,对职业前景的正面预期提升22个百分点。与此同时,58%的员工表示即使企业未授权也会自行使用AI工具,形成“影子AI”现象,带来数据安全与合规风险。这说明,企业当前最大的短板不在技术,而在治理与制度供给。 前沿领域方面,AI代理正处于“认知领先、应用滞后”的早期阶段。73%的员工认为其将在未来3至5年内发挥重要作用,但仅33%真正理解其运作机制,目前仅13%的企业实现流程级整合,64%仍停留在试点阶段。缺乏人类监督、价值对齐问题及算法偏见,成为制约其规模化落地的主要障碍。这意味着下一轮竞争将围绕“自主系统的可控性”展开。 整体来看,亚太地区正站在从“应用领先”迈向“价值领先”的临界点。短期内,AI将持续释放个体生产率红利;但中长期竞争,将取决于企业是否能够将AI嵌入核心流程、重构组织形态并完善治理体系。若亚太企业能够从“工具部署”转向“系统重构”,并同步推进人才再培训与制度建设,其领先优势有望从规模扩散升级为结构性优势。 u200b文档链接将分享到199IT知识星球,扫描下面二维码即可查阅! 更多阅读:TechEquity:2025年人工智能与劳动力发展报告波士顿咨询:AI成熟度矩阵波士顿咨询:不断扩大的AI价值差距工作中的AI:亦敌亦友波士顿咨询:GenAI不仅能提高生产力还能扩展功能波士顿咨询:2025年AI雷达报告谷歌推出人工智能工具筛查恶意言论Similarweb:2025年生成式AI全球行业趋势报告波士顿咨询:2024年消费者AI认知调查Accenture:调查显示企业不愿花钱对员工进行人工智能培训波士顿咨询:CMO如何在动荡时期扩展生成式AI104市調中心:App熱潮不退 消費者最愛哪些App?波士顿咨询:2025年全球财富报告GSMA:人工智能赋能安全应用案例集FICO:2021年负责任的人工智能报告
选择产业:
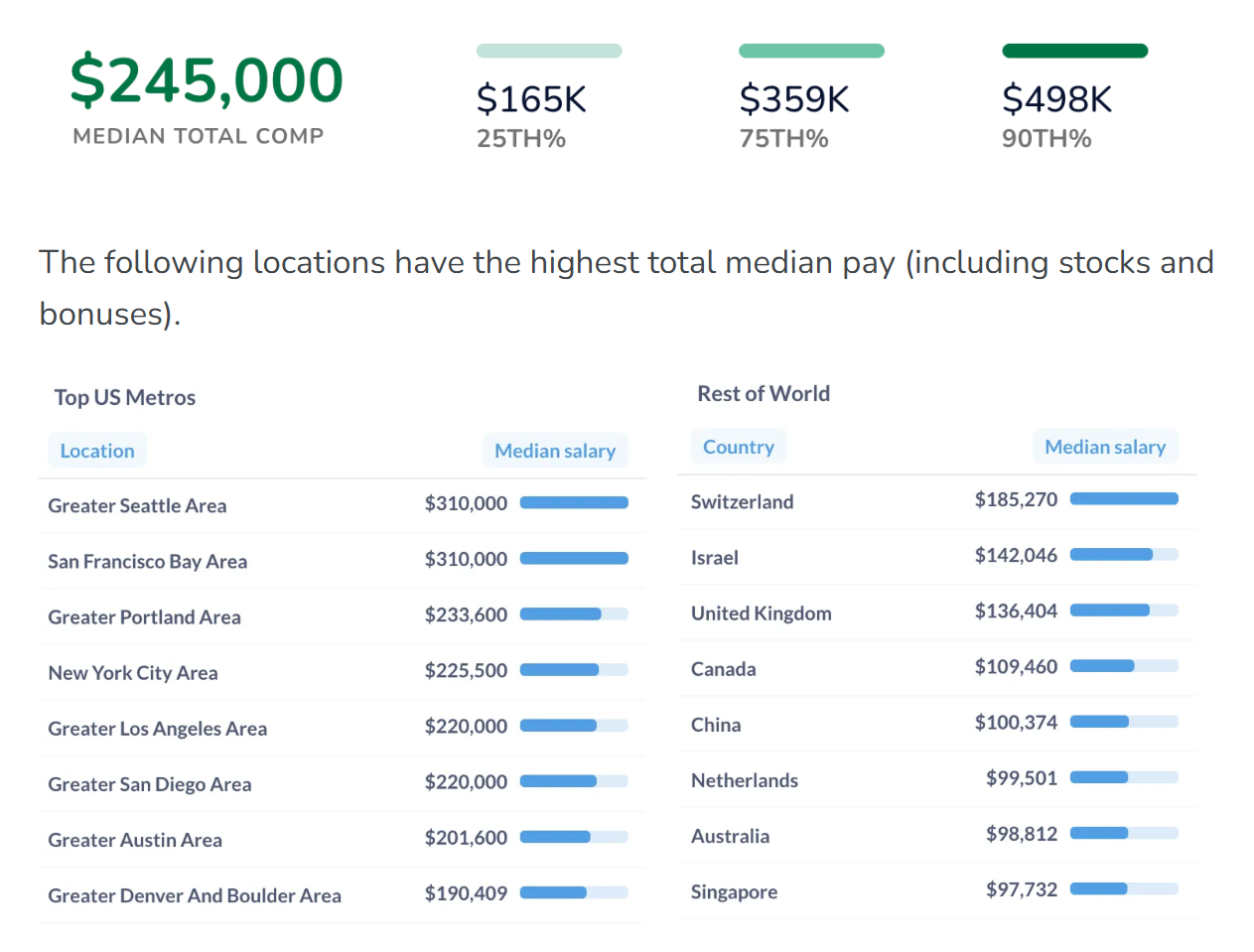








共77727条记录
- 1
- 2
- 3
- 4
- 6478

