周末文摘 | 融合大语言模型和提示工程的医用电气设备标准文件抽取方法研究

专属客服号

微信订阅号
大数据治理
全面提升数据价值
赋能业务提质增效


引用本文
朱婉婷,张培茗*,夏文科,李天纯,王丽.融合大语言模型和提示工程的医用电气设备标准文件抽取方法研究[J].中国食品药品监管,2026(2):34-43.
融合大语言模型和提示工程的医用电气设备标准文件抽取方法研究
Research on an Extraction Method for Medical Electrical Equipment Standard Documents Integrating Large Language Models and Prompt Engineering
朱婉婷
上海理工大学健康科学与工程学院
ZHU Wan-ting
School of Health Science and Engineering, University of Shanghai for Science and Technology
张培茗*
上海理工大学健康科学与工程学院
ZHANG Pei-ming*
School of Health Science and Engineering, University of Shanghai for Science and Technology
夏文科
上海理工大学健康科学与工程学院
XIA Wen-ke
School of Health Science and Engineering, University of Shanghai for Science and Technology
李天纯
上海理工大学健康科学与工程学院
LI Tian-chun
School of Health Science and Engineering, University of Shanghai for Science and Technology
王丽
河南省药品评价中心
WANG Li
Henan Drug Evaluation Center
摘 要 / Abstract
目的:传统的实体关系抽取技术在没有数据集的情况下依赖大量的人工标注,费时费力且难以满足高效处理数据的要求。针对该情况,本文提出运用大语言模型(LLMs)和提示工程技术对医用电气(ME)设备标准文件进行实体和关系的抽取。方法:设计流水线式和端到端式2 种提示词模板,同时从修改示例数量的角度测试提示词模板对大模型的抽取效果。结果:端到端式提示词模板的F1 分数比流水线式更高,且合适数量的示例可以提高LLMs 的抽取准确率。结论:本文提出的ME 设备标准文件提示词模板有一定的有效性,可用于完成ME 设备标准文件抽取三元组的构建。
Objective: Traditional entity-relation extraction methods rely heavily on manual annotation in the absence of labeled datasets, which is time-consuming and labor-intensive and fails to meet the requirements of efficient data processing. To address this issue, this paper proposes the application of large language models (LLMs) combined with prompt engineering to extract entities and relations from medical electrical (ME) equipment standard documents. Methods: Two prompt templates, namely a pipeline-based approach and an end-to-end approach, were designed. In addition, the impact of different numbers of in-context examples on extraction performance was evaluated. Results: The experimental results show that the end-to-end prompt template achieved a higher F1 score than the pipeline-based approach. Moreover, an appropriate number of examples significantly improve the extraction accuracy of the LLMs. Conclusion: The prompt templates proposed for ME equipment standard documents demonstrate practical effectiveness and can be used to construct entity–relation triplets from standard documents.
关 键 词 / Key words
大语言模型;标准文件监管;提示工程;知识抽取;医用电气设备
large language models; standard document regulation; prompt engineering; knowledge extraction; medical electrical equipment
基金项目
上海理工大学- 临港创新中心专业学位研究生实践基地(2025-009)

在当今医疗行业快速发展的大背景下, 医用电气(medical electrical,ME)设备标准文件是医疗设备研发、生产及监管的核心依据,其内容涵盖复杂的技术参数、安全要求与条款关联关系等。因此,如何高效快速地理解并掌握标准文件知识是监管部门面临的一项艰巨任务。已有研究表明,知识图谱是一种用于知识的表示、组织与存储的图结构模型,可以直观地展示实体及其关系和属性,并将不同实体间的复杂关联清晰地呈现出来,涵盖了详尽的实体信息与多样的关联模式[1]。
构建知识图谱的核心任务是知识抽取。然而,在对标准文件进行实体和关系提取时暴露出诸多问题:一方面,如采用深度学习模型抽取,则依赖大规模标注数据训练,但目前ME 设备标准文件没有相应的数据集且此类标准文件中涵盖大量专业术语和复杂关系,标注起来既耗时又耗费人力,难以满足高效处理需求;另一方面,如直接采用大语言模型(large language models,LLMs)抽取实体和关系,则会因标准文件专业性术语密集且小众,LLMs 缺乏对此领域术语的先验知识学习,而在抽取过程中易出现理解偏差和准确性不足的情况。
为解决上述问题,本文提出设计一套面向ME 设备标准文件垂直领域的提示学习方法,引导LLMs 逐步完成这一领域实体和关系的三元组抽取任务。主要包括:① 分别设计2 种ME 设备标准文件的提示词模板,包括先抽取实体再抽取关系的提示词模板和实体关系联合抽取的提示词模板。并比较2 种设计方式对于ME 设备标准文本的抽取效果。②使用不同LLMs 做知识抽取,并对比不同LLMs 的语义建模优势。选择理解ME 设备标准文件的文本实体和隐含关系更优的LLMs 进行后续实验。③在提示词模板中添加由少到多的示例。探寻给出示例的多少是否影响提示词模板对ME 设备标准文本的知识抽取。通过对提示词模板的研究,本文旨在为智能化解读ME 设备标准文件提供参考。

01
实体关系抽取方法
1.1 经典抽取方法
实体关系抽取技术发展经历了从基于规则的方法到基于深度学习的方法的演变。早期的抽取技术主要依赖人工制定的复杂语法和语义规则,需要相关领域专家深度参与规则设计,虽然能针对特定领域实现精准抽取,但存在规则构建成本高、领域迁移能力弱等固有缺陷[2]。随着统计机器学习的发展,支持向量机[3]、条件随机场[4] 等模型逐渐应用,这些方法虽降低了对领域知识的依赖,但仍需人工设计特征模板并依赖大规模标注数据,实际应用中面临特征工程复杂和标注成本高的双重挑战。近年来,深度学习的突破性进展彻底改变了技术范式,形成符号表示、上下文编码和解码三层架构。在符号表示层,从早期的词袋模型逐步演进到基于Transformer 的动态嵌入技术,特别是BioBERT[5]、PubMedBERT[6] 等医学专用预训练模型,通过海量生物医学文献的迁移学习显著提升了语义理解能力。上下文编码层常采用卷积神经网络[7] 和循环神经网络[8]架构,前者捕捉局部特征模式,后者建模长距离序列依赖,旨在为后续解码奠定基础。面对医学文本特有的实体嵌套和关系重叠难题, 解码层创新性地提出了CasRel[9]、TPLinker[10] 等联合抽取框架,通过指针网络实现实体与关系的并行识别。
1.2 大模型抽取方法
尽管基于深度学习的方法能显著提升模型性能,但仍存在预训练模型参数量庞大、长文本处理能力有限、解码算法复杂度高等技术瓶颈[11]。自ChatGPT 引领LLMs 技术浪潮以来,其在医学文本处理中的多任务能力得到验证。研究表明,LLMs 通过超大规模无监督预训练形成的深层语义网络,较传统BERT 类模型具备更精准的上下文建模能力,在命名实体识别、关系抽取等任务中展现出显著优势[12]。早期应用主要依赖领域微调策略,即利用目标领域数据对模型进行参数调优,然而该方法需消耗庞大计算资源且依赖硬件条件,实施门槛较高。提示学习是另一种高效利用LLMs 进行知识提取和任务执行的技术[13],其核心是通过设计特定结构的自然语言指令,引导模型基于预训练阶段内化的知识体系完成目标任务。提示学习不仅节省了硬件资源和数据准备成本,还提高了模型的灵活性和适应性。通过提示可让LLMs 能够遵循人类指令完成相关任务,使得知识抽取任务的范式由微调向零样本或少样本转变[14],且LLMs 在完成具体任务时不需要更改模型参数。这表明LLMs 不再局限于具体的某一个任务,而是可以实现多种任务共用一个LLM。
为精准激活LLMs 的领域知识响应能力,需构建语义适配的指令架构。Hu 等[15] 的研究表明了提示词模板在复杂临床数据的命名实体识别任务中的潜力,其设计并评估了带有任务描述和格式规范的提示词;Chen 等[16] 提到精细的提示设计可以提升少量样本学习任务的表现,其设计了特定提示词模板,揭示了个性化提示的重要性。时宗彬等[17] 在设计材料实体和类型识别时,采用面向核心句、实体及关系抽取的3 种提示词模板进行抽取,并设计模型角色、任务说明、具体示例和待抽取文本4 个部分;张昆等[14] 在抽取故障文本时设计了两阶段提示词模板,分别面向领域概念层和数据抽取层。这些研究都为本文的提示词模板设计提供了参考思路。Zhang 等[18] 构造了零示例和单示例的关系抽取提示词模板,并在3 个标准数据集上观察了生物医学实体之间的语义关系。

02
研究方法
考虑到标准文件的复杂性和差异化,并基于上述相关研究的启发,本文设计的提示词混合了5 个部分:角色扮演、目标生成、提供示例、输出要求和待抽取文本。此套提示词模板采用的核心设计原则聚焦于双重优化的目标:一方面,通过结构化约束机制抑制模型生成无关内容;另一方面,构建具有可解释性的输出格式以提升结果可靠性。总体技术流程如图1 所示。
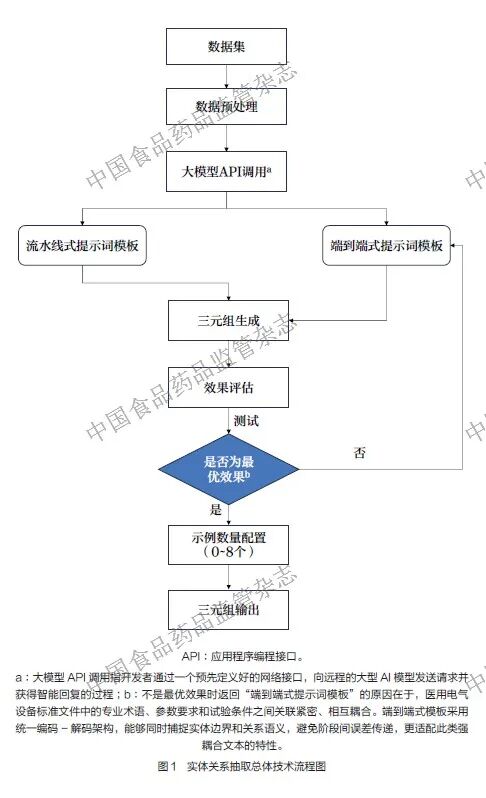
随着大语言模型的发展,非结构化文本中的知识抽取变得更加智能化[19]。LLMs 可通过上下文学习(in-context learning,ICL)方法理解上下文中的隐含含义,即设计任务相关的指令形成提示词模板,利用少量标注样本作为提示,引导模型在新的测试数据上生成预测结果。设语言模型为M,其参数为θ,基于提示的ICL 的实现过程如公式(1)所示。其中,xprompt 表示提示指令;xquery 表示待预测的输入;C 表示上下文文本集合。从公式可以看出,LLMs 的文本生成过程不仅受到原始输入数据的语义约束,更受提示词模板的结构化引导调控。这表明语义目标相同的提示框架可能因语言表述差异导致输出结果产生系统性偏差。因此设计出一套高效的提示词模板,可以提高ME 设备标准文件知识提取的效率。
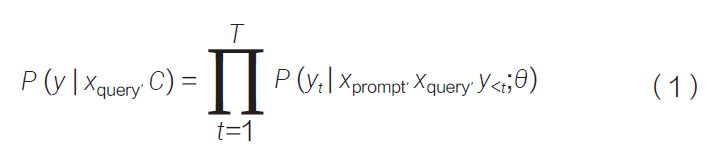
2.1 提示词模板组成
提示词模板的设计准则为:在保证输出结果准确且易解释的前提下,减少LLMs 的幻觉[17]。一个相对完整的提示词模板构成应包含4 个部分:①上下文或背景信息输入。②明确目标或主题。③细化任务描述。④规定输出要求。具体提示词模板的结构如图2 所示。
在LLMs 的使用场景中,上下文或背景信息是指为LLMs 提供的辅助信息,帮助LLMs 理解生成内容的语境、背景或领域相关性,从而生成更符合需求的内容。历史输入、领域元数据(即为源文本描述)、实体集、关系集等都可以作为辅助信息来帮助LLMs 更准确地识别和处理源文本中的领域关键词。明确目标或主题是指直接告诉LLMs 需要生成的内容核心或主题。这部分决定了生成内容的主要方向,确保LLMs 能清楚地理解任务要求并聚焦于正确的方向。细化任务描述指进一步明确任务的具体要求,包括重点内容、细节要求等,通过细化这些要求可以帮助LLMs生成更精确的内容,从而提高任务的完成效率。规定输出要求指明确模型生成内容的具体格式、结构和标准。本文主要输出三元组的形式。
2.2 提示词模板设计
鉴于标准文件文本的复杂性和术语定义的规范性,本文在提示词模板设计中引入示例辅助模型理解,并通过角色设定调整模型在词向量空间中的语义定位,以优化知识抽取的方向性和准确性。通过设计2 种面向ME 设备标准文件知识抽取的提示词模板并进行对比实验,选取效果更优的模板,然后探究示例数量对标准文本抽取效果的影响。
2.2.1 实体关系解耦合抽取提示词模板
在深度学习模型的实体关系抽取任务中,流水线式实体关系抽取范式与端到端联合抽取方法的对比研究已成为重要研究方向[20]。值得注意的是,当LLMs 应用于未接触的特定领域时,模型对领域特征的捕获能力与提示词模板中领域知识的嵌入方式呈现强相关性,因此本文设计2 种提示词模板来提高实体和关系抽取的准确率。采用分步处理机制,即将知识抽取过程解耦为实体识别与关系构建2 个独立阶段并给出1条示例,具体模板设计如图3* 所示。

2.2.2 实体关系联合抽取提示词模板
区别于上述流水线式抽取范式,本文的另一种设计方式采用了端到端处理机制,采用统一编码- 解码架构直接生成三元组(头实体、关系类型、尾实体)。给出1 条示例的实体关系联合抽取提示词模板如图4* 所示。

2.2.3 改变示例数量
提示工程中示范样例(demonstration examples)的数量与抽取目标类型之间可能存在相关性。研究表明[2],逐步增加提示词模板示例能够有效增强模型对特定关系语义特征的捕获能力,进而提升对隐含关系的抽取能力。本文设计了0~8 种示例数量,以观察标准文本的抽取准确率是否与示例数量相关。给出3种示例时的提示词模板如图5*所示。

2.3 评价指标
本文采用F1 分数作为ME 标准文件实体关系抽取任务的核心评价指标,要求模型输出的候选关系三元组与人工标注的基准数据集保持一致,若任一维度的预测结果出现意思偏差、类别误判或关系表征偏差,则该三元组将被判定为误判或漏判实例。基于该评估框架,模型性能通过精确率(precision)、召回率(recall)及其调和平均数(即F1 分数)进行量化分析,其数学表达如公式(2)~(4)所示。其中TPi 表示完全匹配的正确预测数,FPi 和FNi 分别代表误判及漏判的三元组数量。


03
实验结果
本节通过实验验证所提方法的有效性,首先介绍数据集与实验设置,随后基于三元组结构验证提示词模板设计的性能,最后对比分析不同LLMs、提示词策略及其复杂度对知识抽取效果的影响。
3.1 实验数据与环境准备
3.1.1 数据集
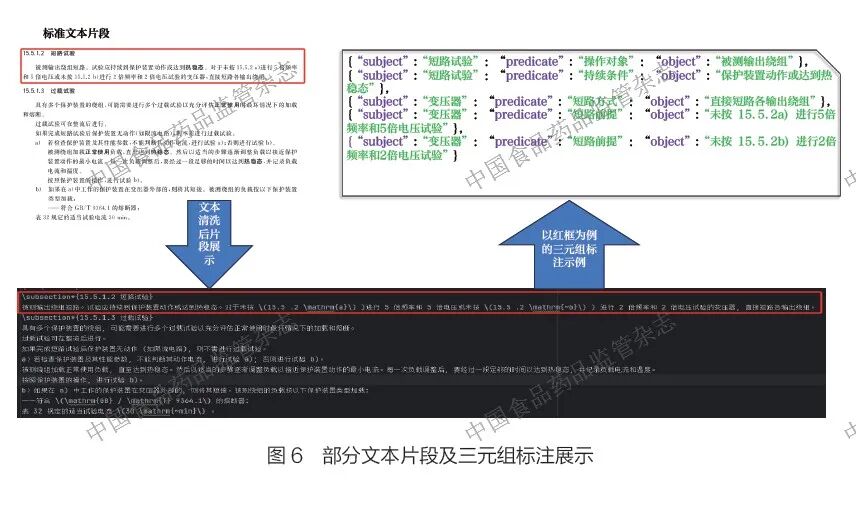
选用GB 9706.1—2020《医用电气设备 第1 部分:基本安全和基本性能的通用要求》作为数据集进行实验。在数据分布上,实体类型涵盖可触及部件相关、环境相关(如富氧环境)、试验相关(如短路试验)、设备相关、控制器相关等;关系类型包括测试条件、操作方式、限定条件及其他关系等。这些内容反映了该标准在设备安全、性能、试验方法等方面的要求及数据特征。部分文本片段示例及其三元组标注示例如图6* 所示。
3.1.2 数据预处理
针对上述文档存在的图片式PDF 问题, 本文采用基于Hugging Face 的GOT-OCR2.0架构进行识别, 该技术通过将PDF 图像转换为张量表示形式, 再构建根据格式识别的提示词( 即OCR withformat),同时对提示词进行编码(tokenizer 操作), 从而实现端到端的文本预测。在文本清洗阶段,本文采用多粒度文本切分技术, 包括页面分割(page segmentation)、段落分隔符(paragraph delimiters)等,确保每个文本块保持语义完整性的同时优化其精炼度,后处理则采用基于规则的正则匹配和语义校验相结合的方法, 对识别结果进行编码校正, 在一定程度上缓解了光学字符识别(opticalcharacter recognition,OCR)技术存在的编码错误、格式紊乱和内容缺失等问题。
3.1.3 温度系数
大模型的温度系数用于控制输出的随机性,其取值范围通常界定于(0,1.0)区间。该超参数值的增大将增强LLMs 生成内容的随机性,反之则强化输出的确定性。鉴于ME 设备标准文件对结构化知识表示的严格要求,本实验将温度系数固定为0.1 进行全流程验证。
3.1.4 应用程序编程接口调用
本文严格遵循原始研发机构提供的标准化接口协议,通过调用各平台提供的应用程序编程接口(application programming interface,API)方式实现对大模型的调用。实验采用单轮会话模式,将数据集与设计的不同提示词模板传输至大模型API 接口,确保各提示词模板在独立黑盒环境执行,既保证了输出结果的可靠性,也避免了文本抽取的上下文干扰。系统开发的软硬件环境配置如表1 所示。
3.2 不同大模型对比实验
为验证不同来源的LLMs对实验结果的影响, 本文选取智谱GLM-4、通义Qwen3、DeepSeek-V3 和DeepSeek-R1 共4 种大模型作为标准文件的实验模型并对比抽取结果(因DeepSeek 是近期推出的大模型,其参数量规模较大,所以在文中选择参数量规模类似的模型进行对比择优),观察其精确率、召回率和F1 分数,结果如表2 所示。
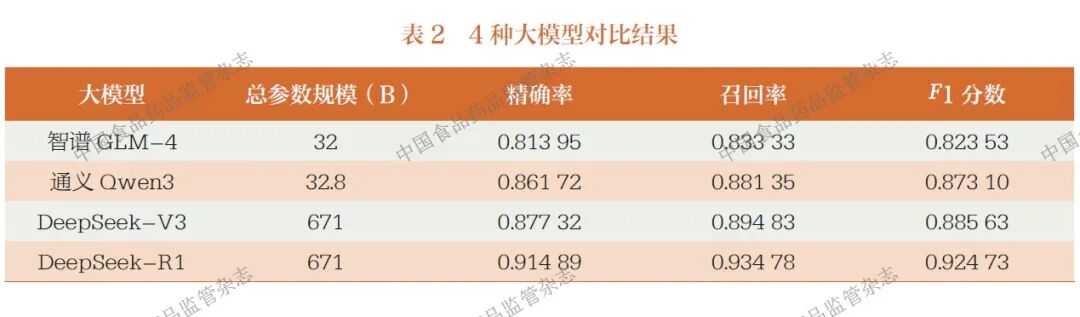
从表2 可以看出, 在给出1 个示例数量的情况下, 智谱GLM-4 的F1 分数最低,输出的三元组中错误实体和漏识别实体较多,但对于短文本和数值型数据识别情况较好。通义Qwen3与DeepSeek-V3 二者的F1 分数相差不多,说明在给出1 个示例的情况下,二者对标准文件的实体关系的理解和归纳能力较强。DeepSeek-R1 是4 种大模型中F1 分数最高的, 说明当DeepSeek 加入思考后对三元组抽取的效果更准确。需要注意的是, 在处理ME 设备标准文件中包含专业术语的长实体时,DeepSeek-R1 虽能识别核心实体,但面对标准领域特有的小众术语仍存在跨章节术语复用场景中的混淆现象,如将“IPX4 防护等级”误判为“试验方法”而非“参数要求”,体现出对领域知识体系深度整合的不足;同时对于标准文件中需结合上下文逻辑推导的隐含关系,其识别率比显式关系稍低,如在“当婴儿培养箱报警器报警时,婴儿舱内声级不应超过80dB (A)”中,易忽略“报警器报警”与“声级限制”之间的触发关系。综合来看,本文实验场景下DeepSeek-R1 仍是处理ME 设备标准文件三元组抽取的最优选择。
3.3 不同提示词模板对比实验
选择DeepSeek-R1 模型为本节的实验模型,比较2 种不同设计提示词模板的抽取效果,如表3 所示。
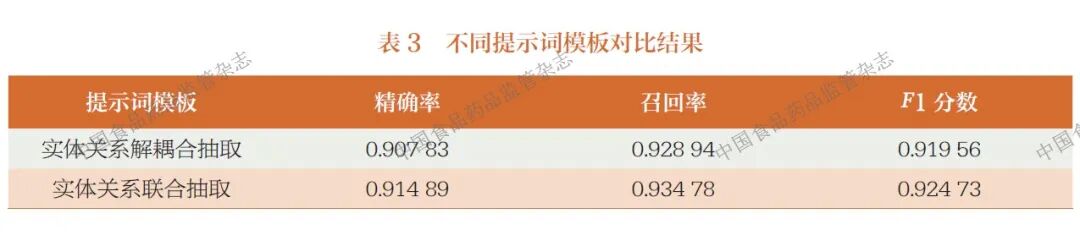
从表3 可以看出,采用分步处理机制的实体关系识别的F1 分数低于端到端的实体关系联合抽取识别,由此推测前者可能更适用于处理分层结构的技术文档,后者适用于处理实体嵌套和关系交叉的文档。而ME 设备标准文件文本多为大量且复杂的实体,同时标准中牵连许多层关系。综合来看,端到端的实体关系联合抽取提示词模板更适用于ME 设备标准文件的抽取。
3.4 改变示例数量对比实验
前述实验表明, 采用DeepSeek-R1 模型结合实体关系联合抽取提示词模板取得的抽取效果最优,因此本阶段实验在该基础上进一步探究提示词模板中示例数量对抽取性能的影响:通过设置0~8 个来源于ME 设备标准文件不同章节的单句示例,以1 个示例的提示词模板为基线,对比分析不同示例数量下模型抽取结果的F1 分数。抽取结果如图7 所示,改变提示词模板中给出的示例数量,大模型的F1 分数也随之而变。当n=0 时,F1 分数仅有0.569 34,比基线(n=1 时)低0.355 39,说明示例能够帮助模型理解所要抽取的实体和关系之间的联系;当1 ≤ n ≤ 4 时,大模型的F1 分数呈正增长状态,说明在增加一定的示例数量后大模型的抽取效果有较大的提升;当4 < n ≤ 8 时,大模型呈不稳定状态,没有严格的直线增长趋势,说明过多的示例并没有让大模型的抽取效果更好,反而会限制大模型的能力。仔细观察图中数据可发现,当示例集中在3~5个时,F1 分数较高。
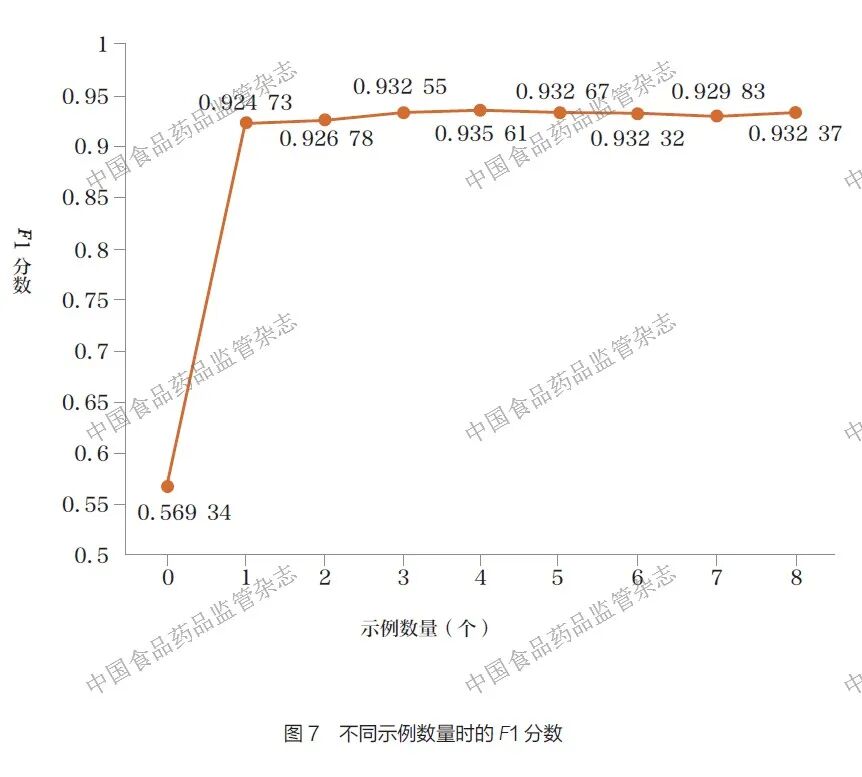
上述结果表明,合适的示例数量可使得大模型对标准文件的实体关系抽取效果较佳,过多或过少的示例都会影响大模型的抽取效果。分析其原因,可能是示例数量会影响大模型的判断力,且不同示例所呈现的信息不同,导致大模型对文件的理解和处理方式产生差异,进而影响其分析和输出结果的准确性。同时,过多的示例会使大模型抽取的词元(token)数量增多,从而增加成本。所以从实际应用角度出发,选择合适数量的示例十分必要。

04
结 语
本文对ME 设备标准文件进行了系统性的三元组抽取研究, 旨在通过融合LLMs 和提示词模板实现对ME 设备标准文件的抽取。首先,本文对4 种不同的大模型进行了测试, 得出DeepSeek-R1 在对标准文件抽取时的表现最佳;其次,设计了2 种提示词模板, 即实体关系解耦合抽取提示词模板和实体关系联合抽取提示词模板,结果表明,在针对包含长实体的标准文件句子开展实体关系抽取任务时,使用实体关系联合抽取提示词模板的效果较好;最后,在模板中加入一定数量的示例,得出在添加3~5 个示例时大模型抽取准确性较高。综上所述,用DeepSeek-R1 设计实体关系联合抽取并给出3~5 个示例的提示词模板,对于ME 设备标准文件中的三元组抽取效果较好。
同时本文也存在一定的局限性:仅选用GB 9706.1—2020一份标准文件进行抽取实验,对其他类型标准文件的适配性和泛化性还需进一步验证;示例内容较为同质,可能会导致模型性能仅适配特定表述风格的示例。未来的工作会将此方法运用到大部分的ME 设备标准文件中,以探寻这种提示词模板方法是否普遍适用;按照关系类型、术语复杂度、表述风格等形成多元化示例内容,量化不同内容特征对抽取效果的影响;设计分层提示结构,改进DeepSeek-R1 抽取标准文件实体关系时存在的隐含关系抽取能力不足、领域术语泛化性有限等问题;引入思维链提示或借助领域微调,优化模型理解形似关系间的细微差异,提升领域术语精度。

第一作者简介
朱婉婷,硕士,上海理工大学。专业方向:医学知识图谱
通讯作者简介
张培茗,博士,上海理工大学,副教授。专业方向:医疗器械监管科学和医疗器械监管数据智能化分析研究

* 扫描文后二维码可查看原图。

请扫描下方二维码查看图3~6 原图
【参考文献】略




编辑:向丽
审核:赵燕宜


