当PC开始本地“养龙虾”:Panther Lake和AI PC的下一步

专属客服号

微信订阅号
大数据治理
全面提升数据价值
赋能业务提质增效

引言:最近OpenClaw如此之火,在AI PC本地、依靠核显养龙虾行不行得通?
最近OpenClaw养龙虾如此之火,有没有想过仅用Panther Lake处理器的核显,在PC本地就有机会让龙虾干活儿?Panther Lake是今年CES期间Intel发布、面向轻薄本和全能本的第三代酷睿Ultra处理器。前不久电子工程专辑详解了这款处理器的架构,并且上手体验了Panther Lake笔记本...
最近Intel在国内举办第三代Intel酷睿Ultra处理器新品分享会,除了携OEM厂商亮相更多采用Panther Lake处理器的笔记本新品,再度强调了这代处理器从架构到工艺各方面的改进,以及性能、效率、AI方面的进化。

如果让我们总结Panther Lake的进化,那么大致可以浓缩为4点:(1)芯片架构与工艺升级:制造工艺更新至Intel 18A——也就是其他foundry厂同代的2nm工艺,CPU/iGPU/NPU架构皆做了迭代;(2)具备低功耗、高能效特性,标称笔记本续航超过20小时;(3)至多12个Xe核心的iGPU核显,游戏性能大幅提升;(4)AI性能与AI PC特性的再进化。
基于此,本文也恰好从4个方面重新解读Panther Lake:尤其在AI PC方向上,Intel又做了些新尝试,包括本地“养龙虾”。
SKU的三档划分
制造工艺和封装层面,因为我们此前已经撰文做过相当详细的解析,无论是Intel 18A工艺的GAAFET结构晶体管、Powervia背面供电,还是Foveros 2.5D/3D先进封装,都令Panther Lake足够代表消费电子领域如今最尖端的半导体技术。高嵩(英特尔副总裁兼中国区软件工程和客户端产品事业部总经理)在分享会上再度提到了18A工艺的几个官方数字:相比Intel 3工艺,每瓦性能提升>15%,器件密度提升30%。
Panther Lake的CPU架构迭代,P-core换用Cougar Cove核心,E-core和LP E-core则迭代至Darkmont核心——至多总共16核16线程(4+8+4);iGPU核显更新到了Xe3核心,至多12个Xe3核心;NPU架构换新到第5代,理论峰值算力50 TOPS。
Intel给出的Panther Lake性能与效率提升数据包括有:CPU部分,在Cinebench 2024单线程测试中,同性能功耗降低至多40%(vs Arrow Lake-H);多线程测试中,同功耗性能提升至多>60%(vs Lunar Lake)或>10%(vs Arrow Lake-H)。iGPU核显图形性能提升>50%(vs Lunar Lake),每瓦图形性能提升>40%(vs Arrow Lake-H)。NPU单位芯片面积的理论性能提升>40%(vs NPU4),同时Panther Lake的AI总算力达到了180TOPS...
这些在电子工程专辑此前的报道文章里均有详细的介绍,包括Panther Lake(第三代酷睿Ultra)处理器的具体型号,及其规格参数。

有所不同的是,这次Intel将Panther Lake的所有SKU划分成了三档:全能旗舰、性能担当、轻薄续航(如上图所示)。其中“轻薄续航”的4个型号,CPU至多8核心、iGPU至多4 Xe核心;“性能担当”CPU至多16核心,iGPU至多4 Xe核心;“全能旗舰”是顶规的至多16核CPU+12核iGPU——此前我们体验的酷睿Ultra X9 388H就在此类。
这三档名称基本也明确了它们的定位,“全能旗舰”强调“全能”,尤其出色的核显性能;“轻薄续航”则更瞄准轻薄本产品,重在更久的续航时间;“性能担当”着眼在搭配独显的笔记本产品,所以PCIe资源给的很充足(PCIe Gen 5 x12, PCIe Gen 4 x8)。
高宇(英特尔中国区技术部总经理)在演讲中说预计其中的“轻薄续航”会成为Panther Lake覆盖用户群最广泛的类别。从处理器成本、Intel 18A工艺的产能爬坡预期,以及由于内存涨价今年PC整机ASP面临提升等多角度来看,这个说法也比较合乎情理。而采用“轻薄续航”系SKU(酷睿Ultra 7 365/355, 酷睿Ultra 5 335/325)的笔记本产品很快也会问世。
再谈低功耗与高能效
Panther Lake最初发布之际,最吸引眼球的卖点无非就是标称27小时的笔记本续航了。我们前不久的Panther Lake笔记本体验也验证了,Office办公续航测试中,99Whr电池容量的Panther Lake笔记本有机会达到20小时续航时长,还是相当惊艳的。联想在分享会上介绍新机时,甚至给即将上市的小新Pro 14 GT AI元启版标了34.8小时的本地视频播放续航时长。

虽然视频播放时长并不能代表笔记本实际使用的续航成绩,但这在以往的x86笔记本上依旧是很难想象的。用高宇的话来说,是“我们用实际测试一扫几十年来整个行业对x86续航不能打的所有偏见”。
所以本次分享会的前一天,Intel就相当自信地开启了“电池续航极限挑战”,分别让3台Panther Lake笔记本去跑3种不同的负载:本地视频播放、UL Procyon Office办公,以及借由OpenClaw部署周期任务(每10分钟访问一个实时更新的数据网络并记录数据),并将这3台笔记本封在盒子里。
到分享会开始之时,这3台笔记本都已经跑了16-17个小时;并且直到分享会结束,也依旧在工作。

分享会结束时已经跑了18个小时半的Panther Lake笔记本还在跑…
有关低功耗另外一个值得一提的数据,是参加本次分享会的Tim(影视飓风创始人)介绍说采用Panther Lake的笔记本,即便电量降到只剩20%,也依旧有余量能坚持2小时的视频或电影播放;所以即便系统提示低电量,也依旧能进行在线会议、视频播放之类的轻负载工作;“就算只剩下20%的电量,也真的不用太焦虑”,“它还能支撑很多的工作场景”。
Intel给出的官方数据是,Panther Lake相比以往的产品平台,在视频播放及在线会议场景中的功耗下降,最高可以达到2.8x(减少65%)——而且是酷睿Ultra X9 388H这种同时强调了性能的顶配款。
冯大为(英特尔公司客户端计算事业部副总裁、个人电脑部总经理)在CES期间受访时,对于Panther Lake实现低功耗的解释就是芯片之上的Low Power Island(低功耗岛)设计,尤其LP E-core(低功耗能效核)具备更强的性能以后,更多负载就不需要跑在挂在L3 cache的P-core与E-core计算单元上了。
我们在评测文章中也提到,这是Intel历史上为数不多的性能上得去的同时,功耗也下得来的CPU产品;相比Lunar Lake(酷睿Ultra 200V系列)这种纯粹以低功耗、高能效为目标的处理器,保持低功耗的同时又有更强的通用性和更好的性能,实在是相当难得。

《三角洲行动》上300fps
除了续航,Intel从去年面向媒体开谈Panther Lake的架构,就已经在宣传12个Xe核心的核显,可媲美入门级独显的图形渲染能力以及能玩3A游戏了。CES期间更是特别给了12 Xe核显以Arc B390的名称,与其Arc独显产品型号对齐;这在我们的测试中,也是尝试探讨的关键话题,惊叹于半导体技术在图形加速器上的时代进步是如此显著。
Intel官方称Panther Lake用上了公司有史以来最大规模的iGPU核显,12个Xe核心相较上代Lunar Lake图形性能提升77%;同时相比橙队的Strix Point,游戏性能领先73%;甚至比独显GeForce RTX 4050(~60W持续输出)还快大约10%。
这次分享会上Intel强调有关Arc B390的关键是XeSS 3——尤其是其中的4x多帧生成技术。XeSS是Intel的AI超分+帧生成技术方法,类似于绿厂的DLSS。XeSS 3新增了基于AI的4x多帧生成能力,即GPU渲染1帧,AI基于此生成3帧,达成理论上的4x游戏性能提升。

此前绿厂对4x多帧生成的期望是,对于高端独显而言令更多游戏达到全高画质+路径追踪4K 240/360fps性能水平;而对Intel的核显来说,4x多帧生成的价值,在于用核显跑3A游戏也能达成流畅体验。
比如已经支持XeSS 3的《赛博朋克2077》和《战地6》,在不启用帧生成的情况下,以酷睿Ultra X9 388H来跑分别能达成48fps和57fps的帧率(1080p Ultra画质,开启XeSS超分);而启用4x多帧生成,帧数提升到146fps和145fps。

现阶段支持XeSS 3的游戏还不多,不过高宇特别介绍如今正火的新版《三角洲行动》已经支持XeSS 3,并现场演示了开启XeSS 3多帧生成以后,Arc B390核显玩《三角洲行动》可达成300fps左右的帧率(上图)——在此体现的应当是核显也玩得了电竞...
AI PC本地靠核显“养龙虾”?
大规模iGPU核显强调的不单是图形渲染能力,AI性能提升也是个中关键。不出意外,分享会的大半篇幅都是给到了Panther Lake驱动下的AI PC的:如文首所述,Intel甚至给出了Panther Lake笔记本完全本地跑OpenClaw的演示,虽然现在还只是个雏形。
在AI全栈技术发展速度以指数级迈进、单位token成本持续大幅下降的今天,更高质量与智商的AI模型得以跑在端侧或边缘。Intel此次特别介绍的,是Panther Lake及其上AI技术栈对Qwen3.5-35B-A3B的支持——高宇说“它非常适合在AIPC本地部署”,不仅因为算力要求适配,而且对于32GB内存的主流笔记本而言,“35b参数能够一次性load到显存中”。

具体到应用上,除了表现它有能力做复杂PDF文档的梳理总结,给我们留下深刻印象的是Intel在现场演示让Qwen3.5-35B-A3B模型用HTML + CSS + JS写个“芯片消消乐”游戏(上图),包括图形元素都要求模型自主完成,最终以单HTML文件跑通——这放在1年前是个不可想象的事情。高宇评价说,该模型在多模态、复杂语言理解、代码生成、Agentic等方面的能力都非常优秀。
所以Intel也尝试基于这款模型驱动“本地龙虾”:Intel自己已经实现的OpenClaw技能(Skill),主要包括有文件整理——帮助用户清理、分类、删除重复文件;报告汇总——比如生成工作日报;图片搜索——除Qwen模型之外,还调用了本地VLM模型,基于模糊语义理解进行本地图片文件的搜索;以及天气数据的可视化——要求龙虾监测天气,每小时都从外部来源抓取当地天气气象信息,并用JS代码生成可视化曲线图、汇总为看板...
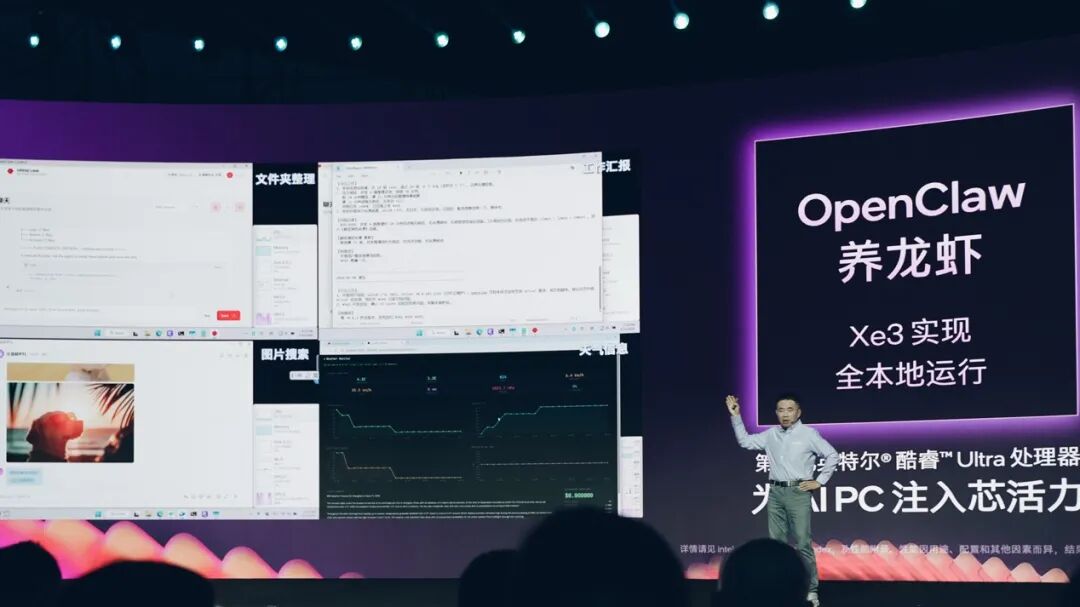
虽说对OpenClaw而言,本地模型的能力和可靠性都存疑,但高宇表示除了减少token焦虑之外,未来本地与云的混合部署会是“龙虾最终的正确打开方式”——即便以上这些还只是demo,“Intel正在做更多的开发和研究”,或许大约还会有更多的成果分享。
我们认为,以现如今AI全栈技术的发展速度,模型智商的进步速度,以及token成本的下降速度,AI端侧应用哪怕仅是1年前的“不可能”现如今也成为了“可能”,消费市场的个人设备“本地龙虾”也未必上不了大众的“餐桌”——虽然现在即便是云上龙虾的风味也依旧说不上多好,但这是AI及AI PC的积极探索。
另外在我们看来挺有趣的一件事是,Intel的软件团队在打造AI技术栈的中间件、库、runtime乃至上层应用的过程中,似乎始终着力在“哪怕是核显,也能加速生产力”的执念上。
比如高宇谈到与像素蛋糕合作,能实现AI批量修图,100张人像照片5分钟内完成中性灰磨皮、缺陷检测与修复、全局调光操作,“是摄影师的必备生产力工具”;还有冯大为演讲中列举剪映的“智能AI粗剪”功能——自动理解用户拍摄视频的内容,生成解说文案,并完成粗剪——在此过程中,AI PC本地负责视频理解工作,与云上模型共同完成粗剪…


本次比较抓人眼球的一个应用是借助AI完成3D打印(上图):从简单的文字提示词开始,通过ComfyUI首先借助Z-image生成2D图片(1024x1024分辨率,20秒)、再用Hunyuan3D将图片转为3D资产(60秒),藉由与创想三维合作、做出输出支持的3D打印机直接进行3D打印...
不管这些多媒体创作类工作流的可控性如何,AI都极大程度简化了原本看起来非常专业、门槛很高的负载,并让普通人凭着几句文字、几次点击就做到从前需要专业人员大量投入的工作。
从去年开始,Intel就在不同的场合演示或宣传过,仅凭核显与AI,大幅加速并完成这类创作过程:其中体现的一部分是软件团队对AI技术与潮流的紧跟(包括这次养龙虾的demo,对Qwen3.5-35b-A3B的支持),另一部分应该是期望做好所谓的端侧“AI普惠”——毕竟用更高算力独显的PC用户仍不是大多数。

虽说要列举AI PC的“杀手级应用”,我们一时半会儿还真想不出来,但AI是确确实实在潜移默化改变着人们的内容消费、数字交互方式,乃至行为习惯的。这些年Intel倡导的AI PC生态覆盖知识助手、办公助手、休闲娱乐、内容创作、行业应用等多个方面,就是个不断探索的过程。
年初的市场分析报告及后续国际电子商情即将发布的4月刊封面故事,我们都对2026年的PC市场给出了相对悲观的预期,尤其是在市场大环境有着如此多的不确定性及存储芯片涨价的阴霾笼罩之时。但AI PC这一热点仍在、AI技术本身也依旧处在高速发展期,此时的技术探索——无论是PC本地养龙虾,还是基于AI工作流的3D打印——都是PC市场持续向前发展的希望。
更多分享会上展示的Panther Lake笔记本新品:

▲ 采用酷睿Ultra X7 358H的小米笔记本Pro 14是这次OEM展示的焦点




THE END
关注“电子工程专辑”加小编微信
现已开放地区群,请发送消息【深圳】【上海】【北京】【成都】【西安】到公众号


