当“架构之源”走向“芯片实体”,Arm用AGI CPU重绘数据中心版图

专属客服号

微信订阅号
大数据治理
全面提升数据价值
赋能业务提质增效
在半导体产业的传统认知中,Arm 是构建数字世界的“图纸提供商”。然而,随着代理式
AI
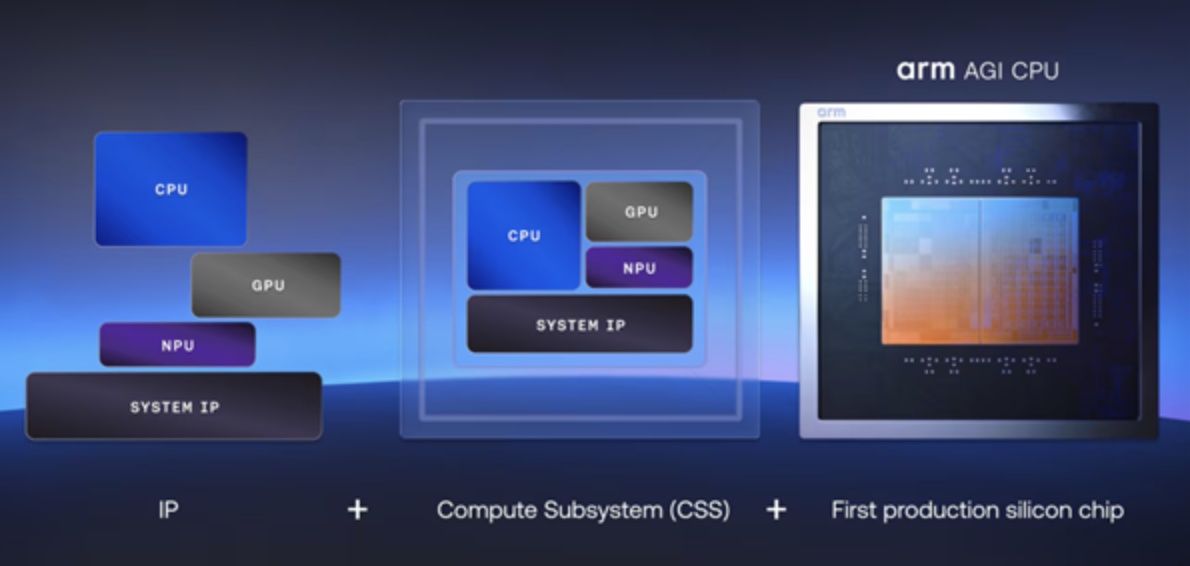
(Agentic AI)对异构计算需求的指数级增长,单纯的 IP 和计算子系统授权已难以完全消纳市场对于算力部署时效性的渴求。Arm AGI CPU的发布,标志着这家处理器架构巨头正式跨越“从设计到实体”的战略藩篱,通过提供量产级自研芯片,补齐了其从 IP、计算子系统(CSS)到量产芯片(Full Chip)的最后一块拼图。这不仅是 Arm 35 年史上的战略质变,更是其在全球
数据中心
去 x86 化、追求极致能效比进程中投下的一枚重磅砝码。

技术突破:3nm 芯粒架构下的“性能密度”重构
在现代数据中心,尤其是代理式 AI 场景下,CPU 的角色正在从单纯的控制平面向高并发任务编排转移。Arm AGI CPU 的硬核实力主要体现在其对“计算平衡”的极致追求。
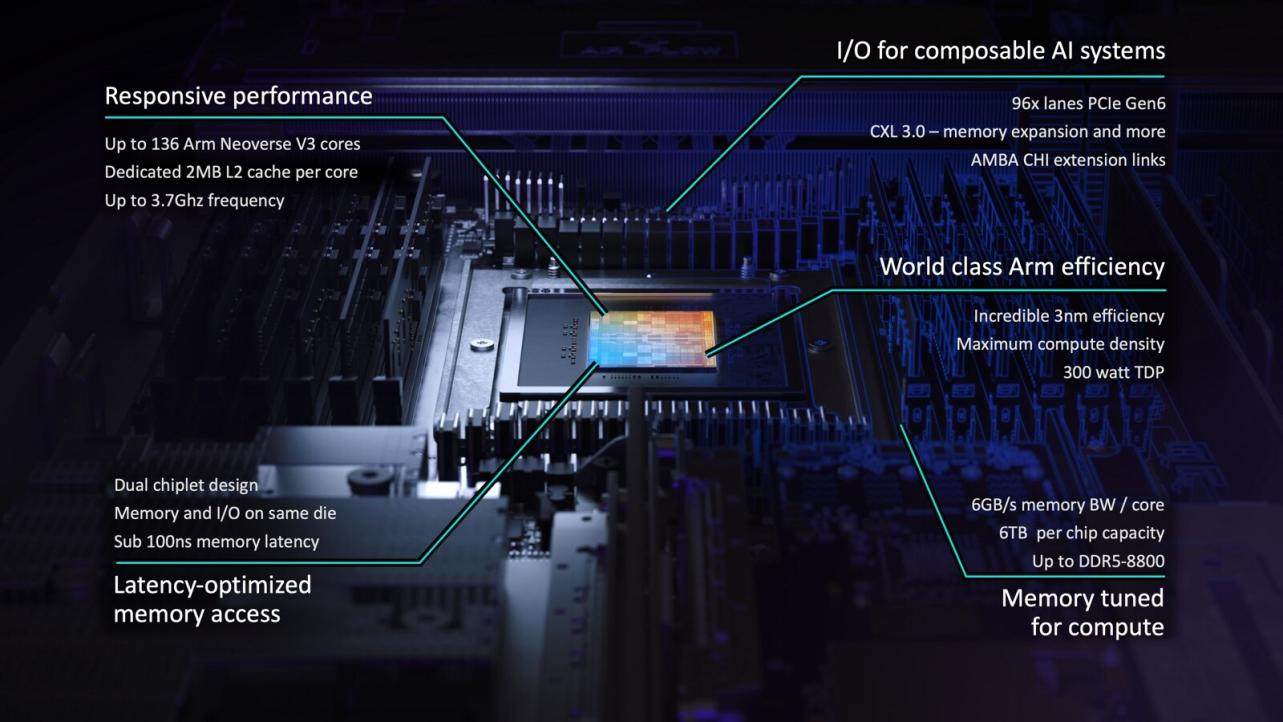
异构集成的成熟芯粒(Chiplet)方案,是 Arm AGI CPU 实现核心规模快速扩张与制造良率平衡的基石。该产品在单颗芯片内集成了两颗规格完全相同的芯粒,并由台积电(TSMC)3nm工艺制造。这种设计在保证良率的同时,实现了核心规模的快速扩张。每颗芯粒均独立集成 CPU 核心、内存接口及 I/O 模块,确保了系统内部数据流的高效交换。
在核心算力层面,Arm Neoverse V3 核心的引入为单线程任务提供了极高性能的确定性保障。 该 CPU 单芯片集成多达 136 个 Arm Neoverse V3核心。在 1OU 双节点参考服务器配置下,每台刀片服务器中集成两颗 CPU 芯片,共计 272 个核心。与传统 x86 架构在持续高负载下因核心资源争抢导致降频不同,Arm AGI CPU 坚持每线程独立核心的设计,这为其在处理大规模并行代理任务时提供了确定的性能输出。
“反常规”的内存布局策略,则印证了 Arm 对代理式 AI 负载中数据搬运特性的深度理解。尽管 HBM(高带宽内存)在加速器中大行其道,但 Arm 在 AGI CPU 上选择了更具通用灵活性的 12 通道 DDR5接口,速率达 8,800 MT/s。其单核心内存带宽达到 6GB/s,时延低于 100ns。这种配置策略显然是为代理式 AI 中频繁的数据搬运、词元(Token)调度与协同编排定制的,而非单纯追求理论峰值算力。
最终,这些底层技术的优化在机架级部署密度上实现了质的飞跃,直接击中了 AI 基础设施的能效痛点。在标准 36kW风冷机架中,Arm AGI CPU 可实现 8,160 个核心的满配部署(共 30 台刀片,每刀片服务器集成2个CPU);而在 200kW液冷方案中,这一数字跃升至 45,000 个核心以上(容纳 336 颗 CPU)。据官方估算,其单机架性能可达最新 x86 系统的两倍以上。
格局陡变:为什么“代理式 AI”需要一颗专属 CPU?
目前的 AI 基础设施正处于从“模型训练”向“智能体协同”的重心转移。所谓代理式 AI,其特征是软件智能体自主交互、实时决策且全年无休。
这一变革直接引发了 CPU 算力需求的非线性增长。由于代理式 AI(Agentic AI)具备自主交互、实时决策且全年无休的特征,整个系统的运行重心正在发生偏移:大部分工作并非发生在加速器的词元生成环节,而是分布在词元的调度、分发、服务管理及跨系统数据迁移上。Arm 首席执行官 Rene Haas 指出,由于智能体可自主生成新智能体并持续运行,市场对 CPU 的算力需求将提升至当前的 4 倍以上。
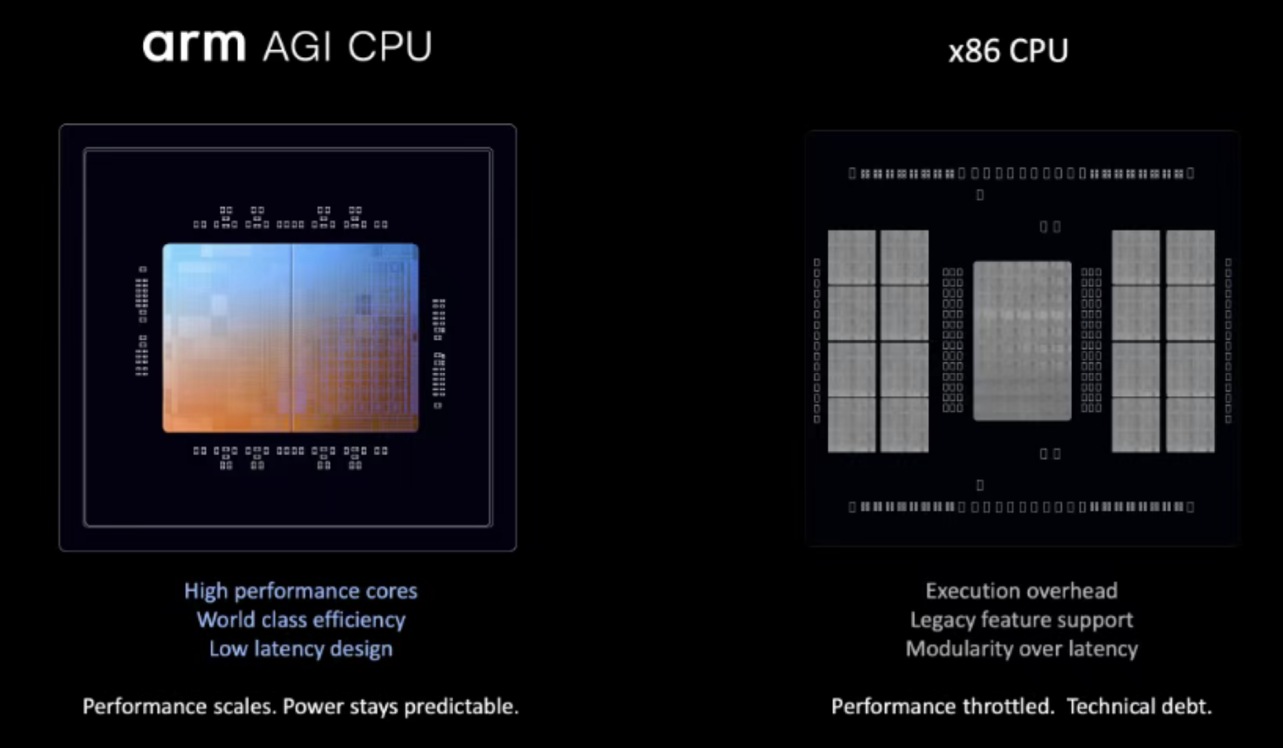
面对现代数据中心严苛的功耗约束,Arm 通过规避 x86 的冗余开销,成功撞碎了阻碍规模化扩展的“功耗墙”。在 300W TDP的约束下,x86 处理器往往面临复杂指令集带来的额外开销。Arm AGI CPU 能够以更简化的架构提供更高的工作负载密度。对于吉瓦(GW)级别的 AI 数据中心而言,采用该方案预计可节省高达 100 亿美元的资本支出(CAPEX)。
关于软件生态这“最后一公里”的挑战,长期由 x86 统治的护城河正在被全球范围内的产业共识所瓦解。随着主流云厂商及 Meta、NVIDIA 等企业在 Arm 生态的持续投入,已有超过一万家企业在数据中心采用 Arm 技术。Arm 云 AI 事业部执行副总裁 Mohamed Awad也在媒体问答中表示,绝大多数 AI 部署及核心软件已实现对 Arm 的原生支持,因此他对 Arm 在数据中心领域承载各类现代工作负载的软件生态布局充满信心。
“我全都要!” Arm 的全栈式跃迁与多维协同逻辑
Arm AGI CPU 的推出,揭示了 Arm 现任领导层更宏大的战略抱负——打破 Arm 延续了 35 年的‘不触碰芯片实体’的行业传统,展现出重塑全球计算供应链的宏大雄心。
1.商业模式的“三轨并行”
Arm 明确表示,未来将同时保留 IP 授权、计算子系统(CSS)授权以及自有芯片销售三种模式。这是一种极其精妙的战略平衡:针对亚马逊、谷歌等具备顶层自研能力的巨头,继续提供 CSS/IP;而针对急于部署代理式 AI 但不愿卷入底层芯片研发周期的 Tier 2 厂商,直接提供量产级芯片。
2. 2030 年的“财务军令状”
Rene Haas 给出了一份极具前瞻性的财务路线图:预计未来 5 年,相关产品的总潜在市场(TAM)约为 1,000 亿美元。到 2030 年,Arm 目标实现:
·公司总营收达 250 亿美元;
·其中芯片业务贡献 150 亿美元,营收规模超越传统 IP 业务预期(100 亿美元);
·每股收益(EPS)达到 9 美元。
3.对供应链的影响
Arm 此次深度整合了台积电(3nm 制造)、美光(内存协同)、安靠(Amkor,OSAT 封装服务)及超微电脑(Supermicro,液冷集群参考设计)。这种深度绑定的链条显示出 Arm 正在从一个“轻资产”的授权商向“重资源”整合的芯片供应商转型。
结语
Arm AGI CPU 的发布,实际上是 Arm 在对
数据中心
客户进行一次“分层管理”。对于头部云巨头,它通过 AGI CPU 展示“样板间”性能,推动 CSS 授权;对于生态其他成员,它直接提供“精装修房”。这颗芯片不仅仅是硅片与电路的集合,它是 Arm 试图主导代理式 AI 时代底层标准的宣言。在 x86 固守领地、RISC-V 追赶后方的夹缝中,Arm 选择了向上突破,直接接管物理实体。这一跃,可能决定了未来十年
AI
算力的基础底色。

