将Agent工作负载的计算效率提升10倍,Gimlet融资8000万美元|AlphaFounders

专属客服号

微信订阅号
大数据治理
全面提升数据价值
赋能业务提质增效

2026年,Agent真正走进了普通用户和企业用户的工作流,接受度大增。Agent生成的token数量是ChatBot的5到15倍,它的需求爆发引爆了推理计算的需求,却也让传统的AI推理基础设施不堪重负。
并且,除了token消耗量增加外,Agent的工作负载所需计算能力与单纯的AI模型推理计算不同,对算力基础设施提出了新的要求,例如模型的推理是计算密集型、解码是内存密集型、而工具调用则是网络密集型 。
斯坦福大学兼职教授、连续创业者Zain Asgar试图用异构计算技术构建独创的多芯片推理与计算云,满足新型AI模型和Agent的推理计算负载需求,试图把AI工作负载的效率提升10倍。
Zain Asgar创立的Gimlet近日获得Menlo Ventures领投的8000万美元A轮融资,Eclipse、Factory、Prosperity7与Triatomic跟投。
此前他们还获得1200万美元的早期融资,包括斯坦福大学教授Nick McKeown、VMware前CEO Raghu Raghuram以及著名芯片投资人陈立武参投。

如果单纯的GPU不能满足所有类型的计算负载,那就建一个异构计算平台来解决
Gimlet由斯坦福大学兼职教授、连续创业者Zain Asgar创立,他此前曾创立了Pixie(开源可观测性工具),之后Pixie被New Relic收购,它的技术成为了Kubernetes的一部分。更早前,Zain Asgar曾在Google Research和NVIDIA工作,他的职业生涯一直专注于高效计算,以及如何在大规模集群上高效地编排和运行计算任务。

Zain Asgar,图片来源:Gimlet Labs
Zain Asgar的联合创始人包括Michelle Nguyen、Omid Azizi和Natalie Serrino,他们是第二次与Zain Asgar一起创业,之前他们在Zain Asgar的上一家公司各自担任重要职位。
近两年,在AI推理计算领域,解耦是一项非常关键的技术,它的本质就是用不同的芯片以及存储,去计算和存储AI推理负载中的不同部分。这项技术之所以出现,在于AI模型及Agent的进化,导致了传统AI推理计算方式的落后。
例如,单个智能体任务可能会通过非线性的分支逻辑,将数十次模型调用、检索步骤和工具调用串联起来。而每个阶段都需要不同的硬件:预填充 (prefill) 是计算密集型的;解码 (decode) 是内存密集型的;工具调用则是网络密集型的。
没有任何一款单一芯片能高效地处理这所有三项任务。GPU适合计算密集型的批量推理,以SRAM储存为中心的专有AI芯片(例如Groq、d-Matrix)适合延迟敏感型工作负载,而CPU则在编排和工具使用这类需求下表现优秀。
预填充 (计算密集型) 和解码(内存密集型)是大模型推理的两个主要阶段。在预填充阶段,输入提示被处理并生成第一个token。随后进入解码阶段,一次生成一个token,直至所有token生成完毕。
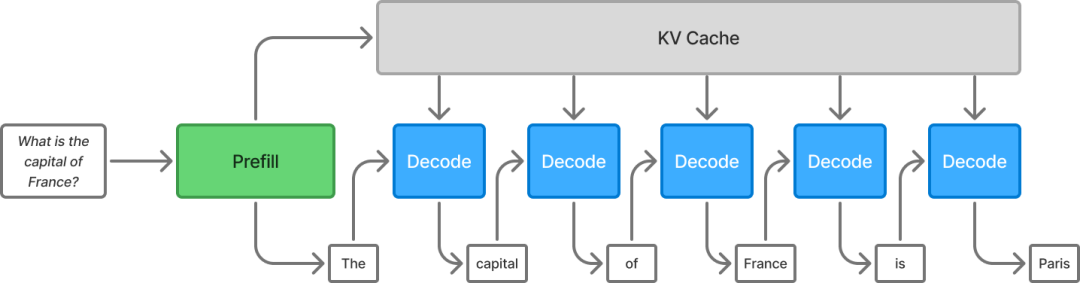
预填充和解码是大模型推理的两个主要阶段。图片来源:Gimlet Labs
当这两个阶段在同一GPU上运行时,它们会相互干扰。计算密集的预填充阶段最终会拖慢正在运行的解码阶段。此外,两个阶段之间缓存数据的重叠度很低,导致缓存争用和内存使用效率低下。
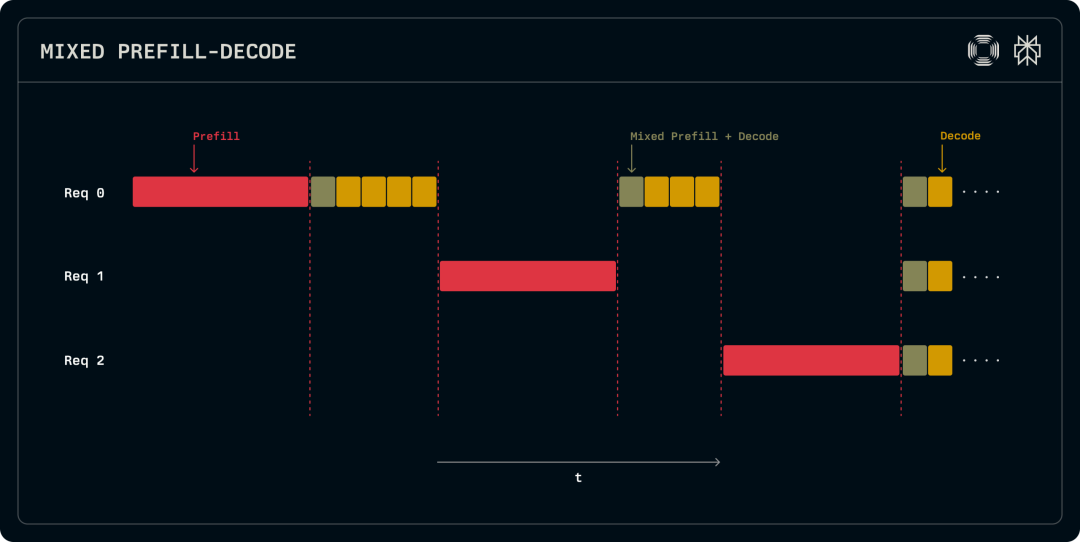
GPU 同时运行预填充和解码阶段的计算负载,会导致工作负载不同阶段之间存在干扰。
图片来源:Perplexity
所以将预填充和解码进行解耦,是目前的一种主要的技术,有Splitwise和DistServe的论文显示,采用“预填充-解码解耦”,AI推理的吞吐量可提升2-7倍。
在实际应用方面,NVIDIA在今年的GTC大会上发布了一项叫解耦推理的技术,它使用一套叫Dynamo的软件,将prefill和attention(高并发运算部分,处理上下文)和decode和token生成(需要极低延迟和极高带宽)拆开,让Rubin GPU(搭载HBM储存)负责prefill和attention,让Groq LPU(搭载SRAM储存)负责decode和token生成。在这种架构下,每兆瓦推理吞吐量最高可提升35倍。
Gimlet对于解耦这项技术做得更彻底,他们通过将AI工作负载与特定硬件解耦,将其分解为各个组成阶段,并将每个阶段路由至最佳的计算资源。
他们以异构计算技术构建首个多类型芯片推理与计算云,将传统GPU与以SRAM为中心的芯片混合部署,使得AI推理的效率将获得颠覆性的提升。
对于预填充和解码的解耦技术,Gimlet在异构、不同供应商的硬件上进行了实验,试图提供更多的工作负载选项,从而提升成本效益并实现更优的权衡。
经过实验,它们发现NVIDIA B200在预填充计算上,最具成本效益,而在解码的计算上,Intel的Gaudi 3表现最佳。
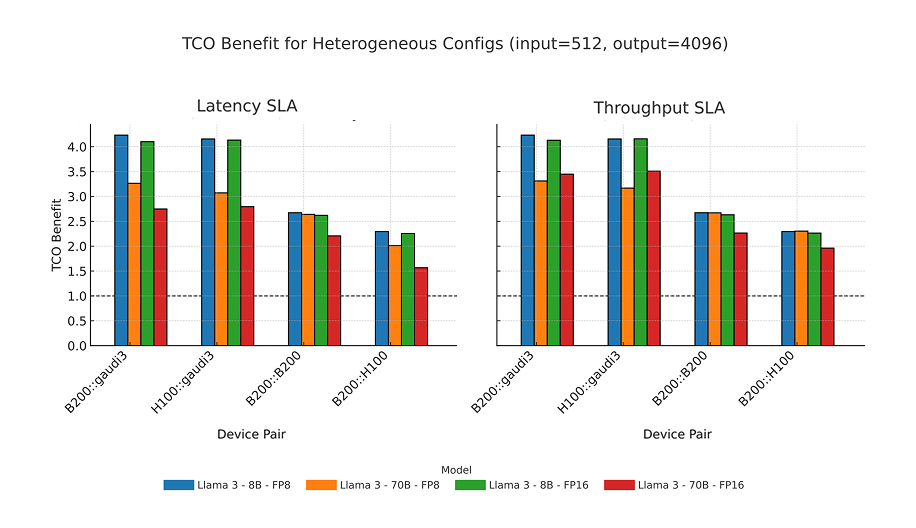
对于解码量大的工作负载,B200:Gaudi3的成本效益优势可高达H100:H100(基线)的4倍。
图片来源:Gimlet,stanford。
于是它们使用B200(计算预填充)和Gaudi 3(计算解码)与其他算力组合进行对比,结果发现,这个组合在延迟敏感和吞吐量敏感的工作负载下, 与作为基准的H100(计算预填充):H100(计算解码)组合相比,TCO(总拥有成本)提升了3-4倍,甚至也优于B200:B200组合。
近期,Gimlet还与AI推理芯片公司d-Matrix合作,进行了另一个实验,它们将d-Matrix Corsair与GPU进行组合,对GPT-OSS-120B模型进行推理。
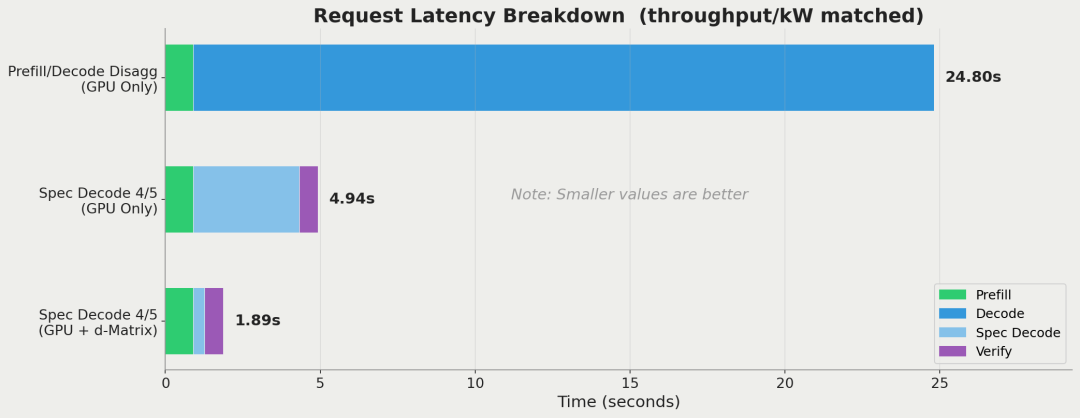
采用d-Matrix Corsair+GPU的结构,可将端到端请求延迟最高降低10倍。图片来源:Gimlet。
具体来说,它们让搭载片上SRAM的d-Matrix Corsair计算推测解码(对内存带宽敏感)的负载,结果发现与在GPU上运行同一推测解码器相比,此举可将端到端请求延迟降低2-10倍,例如,一个原先需要20秒的请求,在2倍提速后可降至10秒10倍提速后更可缩短至2秒。
基于这些异构计算和计算负载解耦的技术,Gimlet构建了一个为运行AI Agent而设计的推理云平台。这个平台会自动将每个工作负载拆解为其组成阶段,并将每个阶段映射到最合适的AI加速器上。计算密集型任务交由高吞吐量GPU处理,内存密集型任务分配给高带宽加速器,网络密集型任务则运行在具备高速互连的节点上。
并且,整个过程完全自动化,开发者不需要重写他们的工作负载。Gimlet在开发者熟悉的环境中与他们对接,允许开发者直接导入现有的PyTorch或HuggingFace流水线。
这个平台的核心技术包括三部分:智能工作负载编排器、编译器、自动化核函数 (kernel) 生成。
智能工作负载编排器能将智能体翻译为计算图 (compute graphs),再将计算图切分为多个分片,并动态地将这些分片分发至可用的硬件上。
编译器负责优化分片的执行,并将其转换为针对特定加速器优化的底层实现。
自动化核函数 (kernel) 生成为不同硬件平台自动创建优化的核函数。
不过,这个平台针对的主要不是个人开发者,而是大型企业客户,自上线以来,Gimlet的客户数量已增至三倍,其中包括一家顶尖的前沿模型实验室和一家超大规模云服务商。
而且Gimlet的推理云平台,不是一个纯软件平台,它包括能跨异构硬件、协同调度复杂智能体工作负载的软件堆栈,以及能将这些硬件物理连接在一起的新型数据中心。
它在数据中心环境中部署系统,已支持NVIDIA、Intel和AMD等主流硬件供应商;自己也在建设一种新型数据中心,通过高速网络将不同类型的多种AI加速器连接起来。

Agent对推理基础设施提出新要求,这蕴藏巨大创业机会
最近一年,可以明显发现,AI的推理,在需求上已经明显变化了,这个需求变化是Agent的发展和普及带来的。
从技术角度,Agent要实现多轮搜索,要调用各种工具,要完成长任务,这都让它需要更多的计算量,以及各种不同类型的计算负载。
从商业角度,推理服务商必须在延迟、吞吐量和成本效益之间寻求平衡。它们不仅要追求性能,更要追求每百万token的成本,甚至后一个指标才是更重要的。
面对这些新的需求,那么相应的基础设施也必须变化,而且硬件和软件都需要变化。
在计算层面,我们看到了计算负载解耦、混合存储架构、以及异构计算,而且计算还得分为数据中心,边缘计算和端侧计算。在软件层面,怎么将算力高效编排,怎么让Agent更好更方便地调用工具,怎么让Agent在云端和本地安全部署都是需要解决好的问题。
那么,既然有新的需求和新的问题,显然就有新的创业机会。在计算层面,面对AI原生硬件和具身智能的热潮,以及未来的巨大潜力,端侧的计算可能机会更大,因为目前的端侧计算芯片显然都还是为手机时代设计的。在软件层面,如果有一个平台能够既保证安全,又能快速方便的部署和推理Agent,那么它也有很好的商业价值。
阿尔法公社已经完成对AgentEarth、共绩科技和万格智元等AI/Agent基础设施领域初创公司的早期投资,我们看到有更多的优秀企业围绕着AI产业革命这个叙事不断涌现。
本文由阿尔法公社原创。
✦

✦


















