看看 Claude Code 怎么做 Harness,这才是 Agent 工程化的真正难点

专属客服号

微信订阅号
大数据治理
全面提升数据价值
赋能业务提质增效

Claude Code 源代码泄露的事情在 X 等平台上引发了极大的关注。
不过,这次更值得关注的不是泄露本身,而是 Claude Code 非常典型的生产级 AI agent harness 设计,向外界完整地展示了一个成熟的 Autonomous Agent 产品应该长什么样,从底层的工程实现到上层的产品决策逻辑,包含了各种细节。
结合 Substack 以及 Hacker News 上对于源代码的分析,我们整理了 Claude Code 在 Agent 架构设计上值得开发者关注、学习的一些要点。
超 22000 人的「AI 产品市集」社群!不错过每一款有价值的 AI 应用。

最新、最值得关注的 AI 新品资讯;
不定期赠送热门新品的邀请码、会员码;
最精准的 AI 产品曝光渠道
01
真正的难点,
在模型之外的 Harness
Claude Code 的架构核心,是一个「Harness」本地运行时的外壳,更多地是依靠 Harness 的工程化与可靠性。
根据公开镜像仓库 nirholas/claude-code,Claude Code 的 TypeScript 源代码跨越了约 1,900 个文件,超过 512,000 行严格类型的 TypeScript,基于 Bun 运行时构建,用 React 和 Ink 驱动终端 UI。
在架构文档里,描述的 Claude Code 系统相当庞大:一个大型 QueryEngine、集中式工具注册表、数十个斜杠命令、持久化记忆、IDE 桥接、MCP 集成、远程会话、插件、技能,以及支持后台和并行工作的任务层。
更准确的比喻是,Claude Code 更像是一个用于软件工作的操作系统,围绕模型堆叠了权限管理、记忆层、后台任务、IDE 桥接、MCP 管道和多代理编排。
Vikash Rungta 在他的逆向工程分析里把这个东西叫做 Harnes:一个本地运行时外壳,把 LLM(Brain)包裹在工具、记忆和编排逻辑(Body)之中,让模型能在现实世界里行动。
要想理解 Claude Code,首先要理解 Agent 架构的三个代际演进:
第一代是 Chatbot,无状态问答;
第二代是 Workflow,用 n8n、LangChain 这类工具把 LLM 嵌进代码驱动的 DAG 流里,代码决定模型下一步做什么;
第三代是 Autonomous Agent,模型控制循环,运行时只是执行器。
Claude Code,就是属于第三代的商业化产品。
Claude Code 的源码也说明了,真正难的是 Harness,给任何支持工具调用的 LLM 提供文件系统访问、shell、分层记忆和声明式扩展能力。所有的这些,都要在一个由可组合权限约束的有界自主循环里运行。
02
TAOR Loop 设计:
Orchestrator 越笨,架构越稳定
Claude Code 的执行引擎是一个叫 TAOR 的循环:Think-Act-Observe-Repeat。这个设计本身不复杂,但背后的设计哲学,很值得关注。
它的 Orchestrator 本身被设计得极其「愚蠢」,只负责驱动循环、执行工具调用、感知结果。所有的推理、决策、何时停止,全部都交给模型。运行时不知道代码是什么,不知道文件在哪,它只是跑循环,让模型决定下一步。
总结来讲:运行时越笨,架构越稳定。把智能下沉到模型,把确定性留给框架。
这和早期 LangChain 试图在框架层做各种「聪明编排」的路线形成了鲜明对比。LangChain 更倾向于把编排逻辑写进代码,用复杂的 Orchestrator 控制 LLM 的每一步。Claude Code 的做法是,所有的推理、决策和停止判断,统统下放给大模型本身。TAOR 循环的核心逻辑大约只有 50 行,但给了模型无限的操作空间。
同样,在工具层遵循这个「笨」的哲学。Claude Code 没有给模型配备 100 个专项工具,而是只提供四种能力原语:Read、Write、Execute、Connect。其中 Bash 是通用适配器,允许模型使用任何人类开发者会用的工具——git、npm、docker,全部通过 shell 组合完成。不要构建 100 个工具,给模型一个 shell,让它自己组合。
随着模型变得更强,脚手架应该变薄,而不是变厚。硬编码的脚手架应该随着模型能力提升而被主动删除,架构随时间推移越来越薄。如果你每次模型升级都要往框架里加更多脚手架,说明你在对抗模型,而不是利用模型。
03
Context Window 是稀缺资源,
不是越大越好
Context 不是越大越好,而是越干净越好。这是 Claude Code 整个架构里贯穿始终的设计原则。
一般来说,Context Collapse 是 Agent 系统最普遍的失败模式。随着对话进行,上下文窗口被填满,记忆退化,幻觉出现,Agent 开始在自己积累的噪音里迷失方向。但 Claude Code 把 Context Window 看成了一种需要主动管理的稀缺资源,围绕 Context 构建了一套自动压缩、子 Agent 隔离和详尽的缓存经济学防御体系。
第一层是 Auto-Compaction。当 Context 使用量达到约 50% 时自动触发,用 LLM 摘要替换原始对话轮次,释放空间的同时保留关键决策。这不是简单地截断历史,而是用摘要压缩,确保重要信息不丢失。这个机制对应的故障模式叫做 Context Collapse,解决方案是:Auto-compaction at ~50% + sub-agents with isolated context windows。
第二层是 Sub-Agent 隔离。把重型的探索、研究任务卸载给独立的子 Agent。子 Agent 运行自己独立的 TAOR 循环,有自己的 Context 预算,任务完成后只把摘要返回给主 Agent。这样,无论子任务消耗了多少 token,主 Agent 的 Context 都不会被污染。
从代码结构上看,这个机制的设计非常精细。子 Agent 运行时:有自己的 maxTurns 上限、有自己的 compaction 机制(独立压缩,不影响主对话)、有自己的 MEMORY.md。主 Agent 派出子 Agent 之后,只等一个 summary 回来,整个子任务的 token 消耗对主 Context 完全透明隔离。
第三层是 Prompt Cache 经济学。 promptCacheBreakDetection.ts 里追踪了 14 个 cache-break 向量,也就是 14 种会让 prompt 缓存失效的情况。代码里还有一个函数叫 DANGEROUS_uncachedSystemPromptSection(),光是这个命名本身就是一种文档:这里加东西要小心,会破坏缓存。代码里还有多个 sticky latches,防止模式切换破坏 prompt 缓存的锁定机制。
当你为每个 token 付费的时候,缓存失效不再是计算机科学笑话,更多的是一个财务问题。
此外,还有一个细节是:Session Continuity。在 Claude Code 里,会话不是一次性的。它们像 git branch 一样运作,可以 checkpoint、rollback,或者把某个探索方向 fork 成一条新路径。这意味着 Context 的管理不只是在单次会话内,而是跨会话的。
04
记忆系统的核心是索引,
不是存储
Claude Code 的记忆系统设计,也非常有意思。
大多数人想象「Agent 记忆」就像一个更大的背包,装得越多越好。但 Claude Code 的记忆系统,更像是一个带有严格图书管理员的档案系统。
核心设计原则是:记忆是索引,不是存储。能从代码库中重新推导出的信息,绝不应该被存储。
从架构上看,Claude Code 的记忆系统分为六层,在每次会话启动时按层加载:
Managed Policy(组织级策略):企业或团队层面的统一规范
Project CLAUDE.md(项目配置):当前项目的特定指令和上下文
User Preferences(用户偏好):个人层面的习惯和偏好设置
Auto-Memory(自动学习模式):Agent 从历史交互中学到的用户模式
Session(会话上下文):当前会话的临时信息
Sub-Agent Memory(子 Agent 记忆):各子 Agent 独立维护的专项记忆
其中,Auto-Memory 循环甚至允许 Agent 学习用户的工作模式,并把这些模式写入 MEMORY.md 供未来会话使用。用户不需要反复解释相同的事情,Agent 会从之前的交互里学习并记住重要信息。
同时,Claude Code 的子 Agent 记忆机制也值得一提。在自定义子 Agent 的配置里,可以设置 memory: user,Agent 会把学到的模式写入 ~/.claude/agent-memory/<name>/MEMORY.md,下次调用时自动加载前 200 行。这意味着每个子 Agent 都可以有自己独立的、持续积累的专项记忆。
更关键的是,这个系统具有主动自我编辑能力。它不仅会记录,还会重写、去重、甚至剪除互相矛盾的信息,过期且无效的记忆在这里被视为「负债」而非资产。
Claude Code 的记忆系统设计,也侧面反映了:在产品层面,记忆不只是一个 Feature,它是决定用户是否继续使用的核心留存机制,因为用户真正期待的是一个「会学习」的 Agent。
05
权限系统的设计更像是 UX 设计,
信任是可组合的
权限与安全问题,是 Agent 走向企业级应用的前提。
Claude Code 的权限系统被设计为一个五档的信任光谱:
plan:只读,完全不能写入,信任级别最低
default:编辑和 shell 操作前都需要询问,标准模式
acceptEdits:自动批准文件编辑,shell 操作仍需询问,中等信任
dontAsk:自动批准白名单内的所有操作,高信任
bypassPermissions:跳过所有检查,仅限托管组织使用,最高信任
每个工具调用都经过静态分析层的多层白名单校验。bashSecurity.ts 里有 23 项编号的安全检查,包括:
18 个被阻止的 Zsh 内置命令
防御 Zsh equals expansion:=curl 这种写法可以绕过对 curl 的权限检查
unicode 零宽字符注入
IFS null-byte 注入
一个在 HackerOne 审查期间发现的恶意 token 绕过
这种可组合的信任光谱,让 Claude Code 能够适应完全不同的使用场景:从什么都要确认的高度受限企业环境,到全速运行的个人开发环境。权限设计更像是 UX 设计。对于 Agent 产品来说,这也是从 Demo 进入企业生产环境的「门槛」。
同时,Claude Code 还有一个更底层、巧妙的机制是,API 请求在 JS 层之下做了身份验证。
在 system.ts 文件里,每个 API 请求都包含一个 cch=00000 占位符。在请求真正离开进程之前,Bun 的原生 HTTP 栈(用 Zig 编写,运行在 JavaScript 运行时之下)会把这五个零替换成一个计算出的哈希值。服务端会验证这个哈希,确认请求来自真实的 Claude Code 二进制文件,而不是第三方伪造的客户端。
之所以用等长的占位符,是为了让替换不改变 Content-Length 头部,也不需要缓冲区重新分配,这是一个很细节的工程考量。整个计算过程发生在 JS 层之下,对运行在 JS 里的任何代码都完全不可见。本质上是在 HTTP 传输层实现的 API 调用 DRM。
这也是 Anthropic 此前向 OpenCode 发律师函背后的技术基础。Anthropic 不只是要求第三方工具不要使用他们的 API,二进制文件本身通过加密证明了自己的身份。OpenCode 社区在收到法律通知后不得不诉诸会话拼接技巧和认证插件,原因就在这里。
06
多 Agent 编排,
从子 Agent 到 Agent Teams
Claude Code 的多 Agent 编排采用了横向扩展的方式,分为两层。
第一层:Sub-Agent
子 Agent 以独立进程方式运行,有自己的 TAOR 循环、自己的 Context 预算、自己的 maxTurns 上限、自己的记忆。任务完成后,只把摘要返回给主 Agent,主 Agent 的 Context 完全不受影响。
Claude Code 内置了三种预设子 Agent,各有分工:
Explore:用 Haiku 模型(速度快、成本低),只有只读工具(Read、Grep、Glob),专门做文件发现和代码库探索
Plan:继承主 Agent 的模型,只有只读工具,专门做代码库研究和规划前的信息收集
General-purpose:继承主 Agent 的模型,配备全套工具,处理复杂的多步骤操作
自定义子 Agent 通过 .md 文件加 YAML frontmatter 定义,可以指定模型(sonnet/opus/haiku/inherit)、权限模式、maxTurns、可用工具白名单、禁用工具黑名单,甚至可以预加载特定的 Skills。存储位置有三种:~/.claude/agents/(用户级)、.claude/agents/(项目级),或通过 --agents CLI 参数指定。
子 Agent 还支持前台和后台两种执行模式。前台模式会阻塞主对话,权限询问和问题会透传给用户;后台模式则在用户继续工作的同时并发运行,权限在启动前就预先收集,如果遇到没有预批准的权限请求,工具调用直接失败,Agent 继续运行。按 Ctrl+B 可以把正在运行的前台 Agent 切换到后台。
第二层:Agent Teams
这不再是主 Agent 派遣子 Agent 的主从关系,而是完全独立的 Claude Code 实例通过共享文件系统协调任务。两者区别:
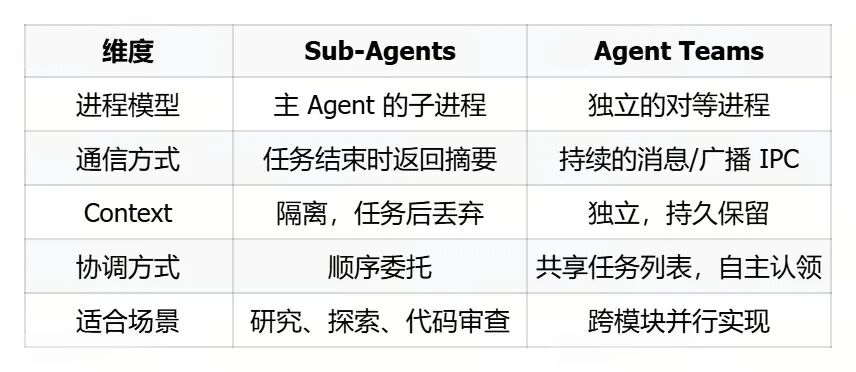
Agent Teams 的协调机制包括:Shared Task List(所有 Agent 可见任务状态,完成当前任务后自主认领下一个未分配任务)、单播 Message(发给特定 Teammate)、Broadcast(发给所有 Teammate,注意成本随团队规模线性增长)、以及 Automatic Idle Notification(Teammate 完成任务停止时自动通知 Lead)。
同时,还有两个专门针对团队的质量门控 Hook:TeammateIdle(Teammate 即将进入空闲时触发,返回 exit code 2 可以发送反馈让它继续工作)和 TaskCompleted(任务即将被标记完成时触发,返回 exit code 2 可以阻止完成并要求修复)。
但 Agent Teams 目前还是实验性功能,需要通过 CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1 环境变量或 settings.json 启用。
07
还没发布的 KAIROS,
一个 Always-On Agent
在这次泄露中,有一个 Claude Code 还未发布的功能 KAIROS,可以在后台持续运行的 Agent。
根据 main.tsx 里的代码路径,KAIROS 是一个功能门控的未发布模式,包含以下特征:
/dream 技能,用于夜间记忆蒸馏(nightly memory distillation)
每日 append-only 日志
GitHub Webhook 订阅
后台 Daemon 工作进程
每 5 分钟的 Cron 调度刷新
把这些特征拼在一起,是一个完全不同的产品形态:常驻后台、持续学习、主动感知代码库变化的 Autonomous Agent。不是你召唤它,它来帮你,而是它一直在,主动为你工作。
现有的 Claude Code 是一个召唤式 Agent:你打开终端,它来帮你,你关掉终端,它就停了。但 KAIROS 描绘的是下一代形态:Agent 在后台持续运行,通过 GitHub Webhook 感知代码库的变化,每天晚上做记忆蒸馏,把当天的工作模式和项目状态压缩进长期记忆,第二天一早已经「预热」好了。
虽然不知道 Anthropic 内部对 KAIROS 的开发已经进展到了什么程度。但 KAIROS 的泄露说明了,Claude Code 的产品野心已经远超「LLM + 命令行包装」,朝着「终端操作系统级 Agent」方向前进。
08
一些彩蛋:
Anti-Distillation 机制、Undercover Mode
此外,在这次泄露的源码里,还有一些非常有争议性的工程决策,被扒了出来。
Anti-Distillation 机制
claude.ts 第 301-313 行有一个叫 ANTI_DISTILLATION_CC 的标志。当它开启时,Claude Code 会在 API 请求里携带 anti_distillation: ['fake_tools'] 参数,服务端会向系统提示中静默注入虚假的工具定义。
逻辑很直接:如果有人在录制 Claude Code 的 API 流量来训练竞品模型,这些假工具会污染训练数据。这个机制通过 GrowthBook 功能标志 tengu_anti_distill_fake_tool_injection 控制,只对第一方 CLI 会话激活。
还有第二层机制在 betas.ts 第 279-298 行:服务端 connector-text 摘要。启用时,API 会缓冲 Assistant 在工具调用之间的推理文本,对其摘要后返回带加密签名的版本。在后续轮次里,原始文本可以从签名恢复。录制 API 流量的人只能拿到摘要,拿不到完整的推理链。
Undercover Mode
undercover.ts 文件大约 90 行,实现了一个单向门:当 Claude Code 在非 Anthropic 内部仓库里使用时,它会指示模型永远不提及内部代号(比如 Capybara、Tengu)、内部 Slack 频道、仓库名称,甚至不提及 Claude Code 这个名字本身。
第 15 行有一条注释写得很清楚:
There is NO force-OFF. This guards against model codename leaks.
你可以用 CLAUDE_CODE_UNDERCOVER=1 强制开启,但没有办法强制关闭。在外部构建里,整个函数会被死代码消除为平凡返回。这是一个单向门。
这意味着,Anthropic 员工在开源项目里用 Claude Code 生成的 commit 和 PR,将没有任何 AI 参与的标记。如何在商业防御需求与 AI 透明度伦理之间做权衡,也是值得思考的事情。


OpenClaw 闭门局:和 30 位创业者一起聊聊,真正值得关注的 Agent 生态位在哪?
Claude Cowork 负责人:别再给 AI 配工具了,给它一台电脑
转载原创文章请添加微信:founderparker

