深度|阿里 ICLR 255 篇霸榜!基座是明牌,系统是暗牌,做实比做强更狠

专属客服号

微信订阅号
大数据治理
全面提升数据价值
赋能业务提质增效

Z Highlights
从论文分布上看,基座大模型吃掉51.8%的份额,多模态感知再切走 20.8%。光是这两个方向,就卷走了超过七成的火力。
如果说基座大模型是明牌,那计算机系统就是阿里的暗牌。表面上看,系统方向只有 5 篇论文,数量少得可怜。但整个 ICLR 2026 在系统方向的占比仅 0.8%,阿里的偏好指数高达 2.44,重仓程度甚至超过基座大模型。
谁能解决泛化问题,谁能压缩系统成本,谁能打通模型落地的最后一公里,谁才是下一个时代的赢家。阿里系的研究重心,已经从做强转向做实。
AI 顶会江湖,风向正在悄然生变。
当全球 5340 篇论文涌入 ICLR 2026,阿里系以 255 篇接收论文、10 篇 Oral 的硬核战绩,拿下 4.8%的全球份额。这不是简单的数字堆砌,在这份成绩单背后,藏着阿里 AI 战略的深层逻辑:从单兵突进转向生态作战,从论文工厂转向产业闭环。
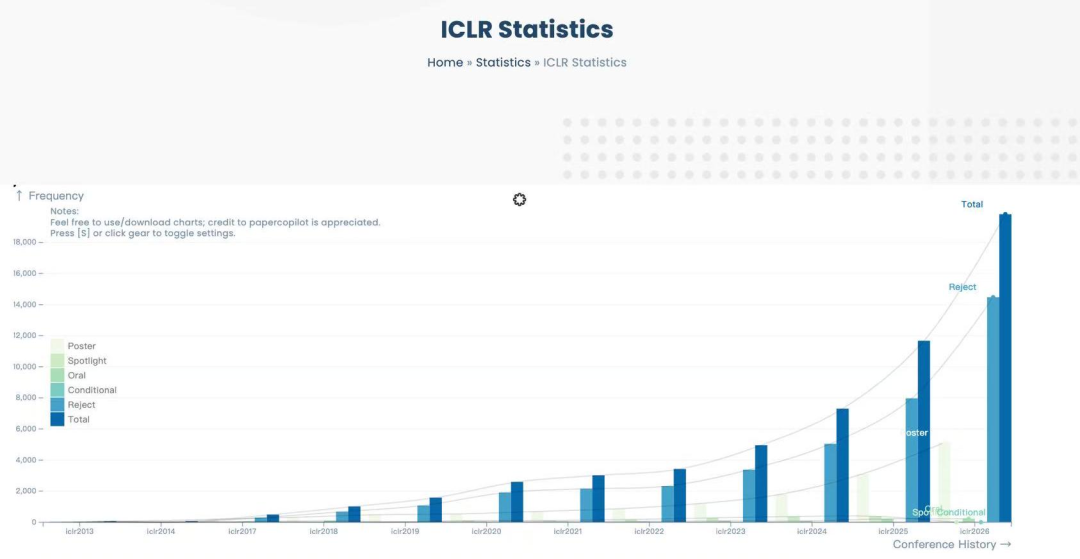
关于 ICLR:国际表征学习大会(ICLR)是深度学习领域顶级会议,与 NeurIPS、ICML 并称机器学习三大顶会,近期被 CCF 评为 A 类会议。2026 年 ICLR 覆盖大语言模型、生成模型、多模态学习、AI 安全、机器学习系统等多个前沿方向。
255 篇背后:一场产学研的铁三角实验
翻开阿里系的论文版图,一个反常识的数据炸场:96.1% 的论文依赖外部合作,纯阿里独立完成的仅占 2.7%。但一个细节更值得玩味:这份庞大的合作名单里,海外高校几乎缺席。
这不是能力短板,而是一场更为极致的本土化闭环实验——阿里正在把自己变成一块磁石,不玩闭门造车的原创神话,而是搭建产业平台 + 国内高校网络的新范式。纯阿里独立完成的论文,只有 7 篇,占比 2.7%。剩下的 97.3%呢?
阿里-高校合作 168 篇(65.9%)
阿里-高校-企业混合 77 篇(30.2%)
纯阿里-企业合作 3 篇(1.2%)
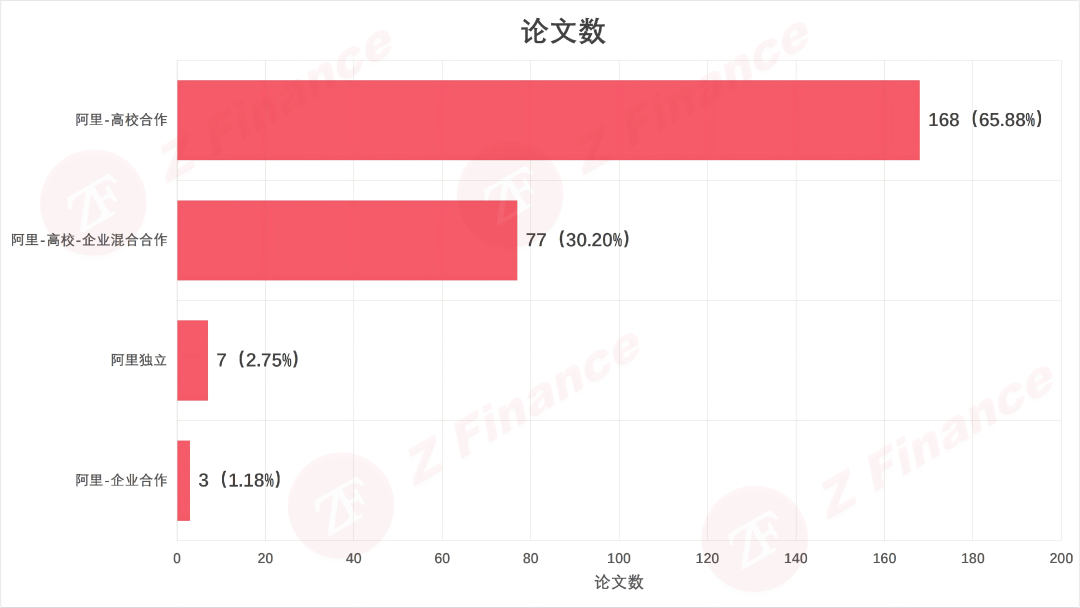
图 7 阿里系论文合作版图分布
本土 AI 全明星阵容包括:
浙江大学 51 篇
清华大学 43 篇
香港科技大学 31 篇
北京大学 29 篇
中科院自动化所 20 篇
甚至连字节跳动(13 篇)、腾讯(9 篇)这些友商,都在阿里系的合作网络里刷脸。在顶会赛场上,竞合关系的边界正在模糊——今天的对手,明天的合作者。
0% 的海外依赖,2.7% 的独舞,96.1% 的群像,阿里在用数据证明:在这个时代,做平台比做孤岛更有杀伤力。这些头部高校不仅是论文产出机器,更是阿里的人才蓄水池和技术风向标。
基座大模型吃掉半壁江山,多模态感知紧追不舍
如果说论文数量是面子,那研究方向就是里子。阿里系的火力高度集中在两大高地:基座大模型(51.8%)和多模态感知(20.8%)。光是这两个方向,就吞掉了超过七成的弹药。
这与 ICLR 的整体趋势同频共振,但阿里的打法更重——当行业还在卷参数规模,他们已经开始死磕可用性重构。10 篇 Oral 论文透露了研究重心正从能力突破转向场景闭环:泛化、推理、效率、落地这四个关键词,构成了阿里 AI 的新坐标系。
过去两年,大模型赛道充斥着大力出奇迹的狂热。但阿里系在 ICLR 2026 的选题,明显冷静了下来。
他们不再只关心模型能做什么,而是追问模型在真实世界怎么用得起来。系统效率优化、复杂环境泛化、推理可靠性保障,这些听起来不那么性感的方向,正在成为新的技术高地。这种转向,与阿里的产业基因密不可分。作为年研发投入超 15%、坐拥数万块 GPU 集群和数十亿级真实业务数据的云服务商,阿里比纯研究机构更清楚:技术价值最终要在产业闭环里兑现。依托 7000 余名技术人才(含 2000+博士)和魔搭社区等开放平台,阿里已经构建起全球领先的 AI 全栈能力。
但 255 篇论文也抛出了一个新命题:当外部合作成为主流产出模式,如何在工程能力、场景需求与学术原创之间找到更深层的平衡?这不仅是阿里的挑战,也是中国产业 AI 的集体课题。毕竟,顶会论文只是入场券,定义下一代 AI 基础设施的能力,才是真正的终局之战。
计算机系统方向偷偷发力,全力押注工程可落地
255 篇论文背后,阿里系的弹药到底投向了哪里?
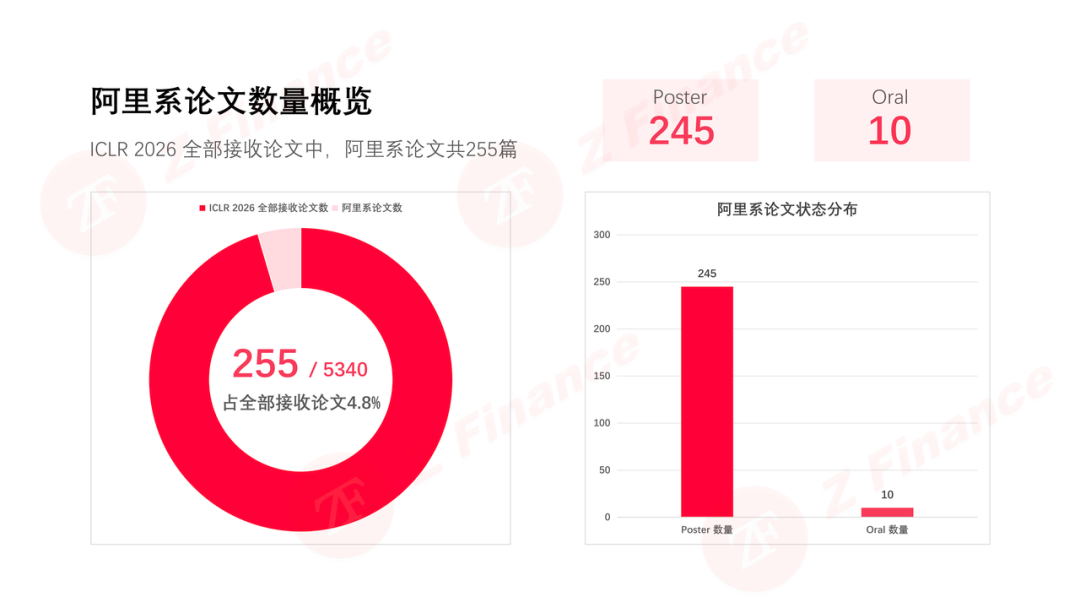
图 1 阿里系论文数量概览
基座大模型:阿里的超配战略
数据不会说谎。ICLR 2026 整体接收论文中,基座大模型方向占 33.2%,而阿里系在这一方向的占比高达 51.8%——偏好指数 1.56,超配幅度接近六成。这意味着当行业还在均衡布局时,阿里选择了把鸡蛋放在最重的篮子里。
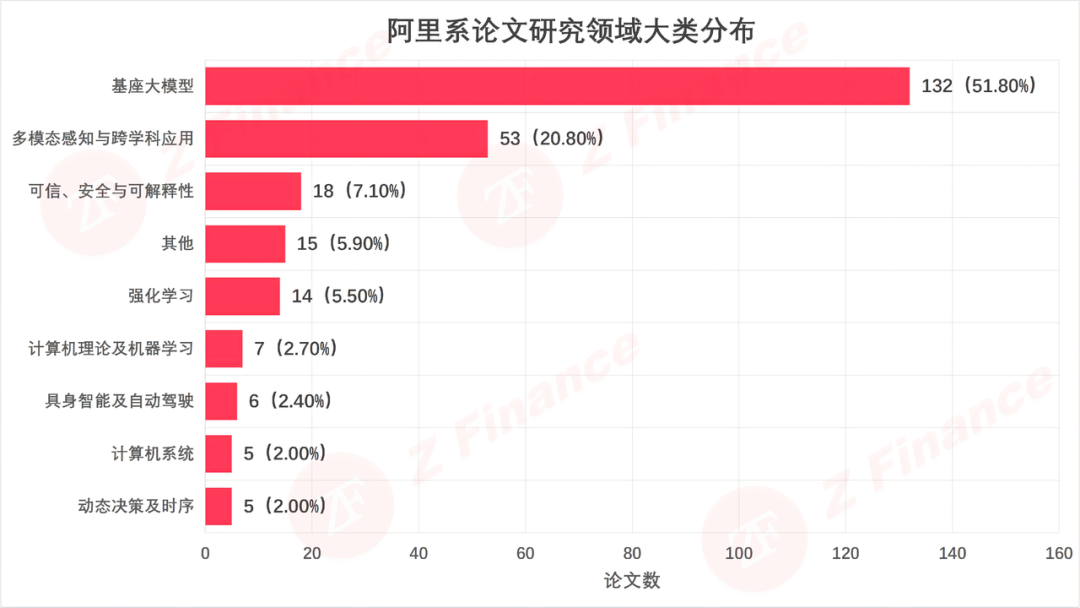
图 2 阿里系论文研究领域大类分布
更细颗粒度地看,阿里系在 foundation or frontier models(含 LLM)方向砸了 72 篇论文,占总量 28.2%;多模态应用 47 篇、数据集与评测基准 30 篇、生成模型 30 篇——从底层架构到上层应用,从训练数据到评测标准,阿里正在构建一套完整的技术闭环。
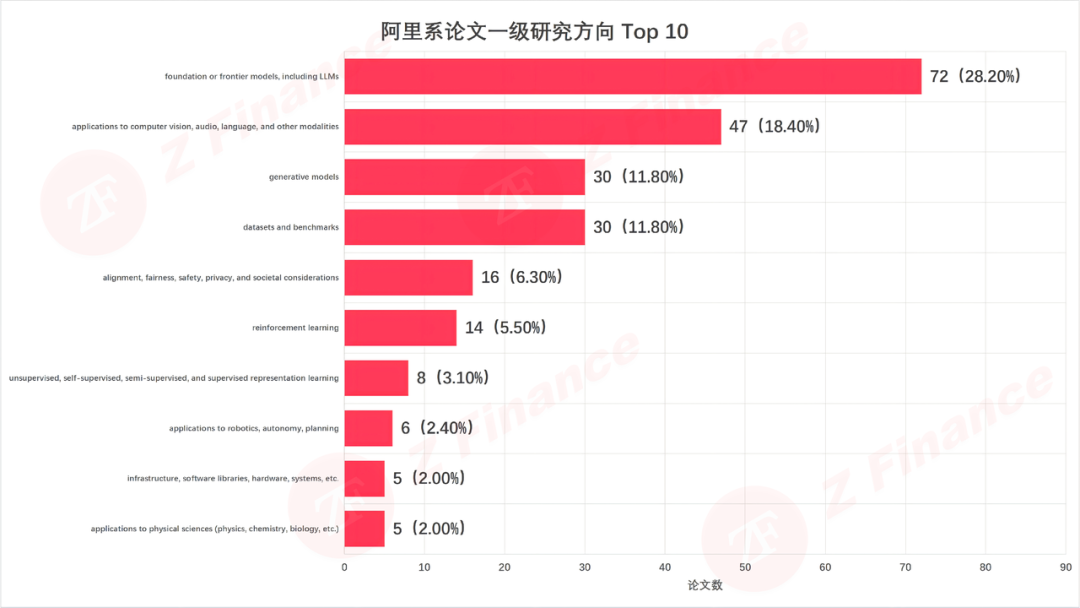
图 3 阿里系论文一级研究方向 Top 10
一个值得玩味的细节是Junyang Lin(林俊旸)一人署名 8 篇论文,其中 1 篇 Oral。这位阿里大模型骨干的选题清单,堪称阿里技术路线的缩影——多模态推理、软件工程智能体、推测式解码、全模态感知...清一色的大模型+多模态主线。
系统方向是被忽视的隐形重仓
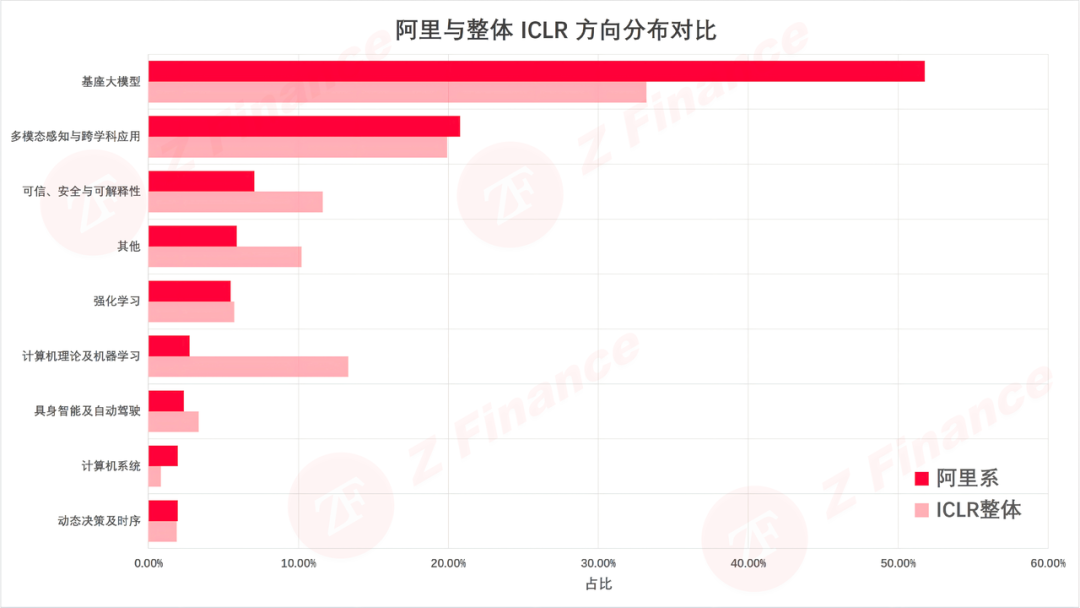
图 4 阿里与整体 ICLR 方向分布对比
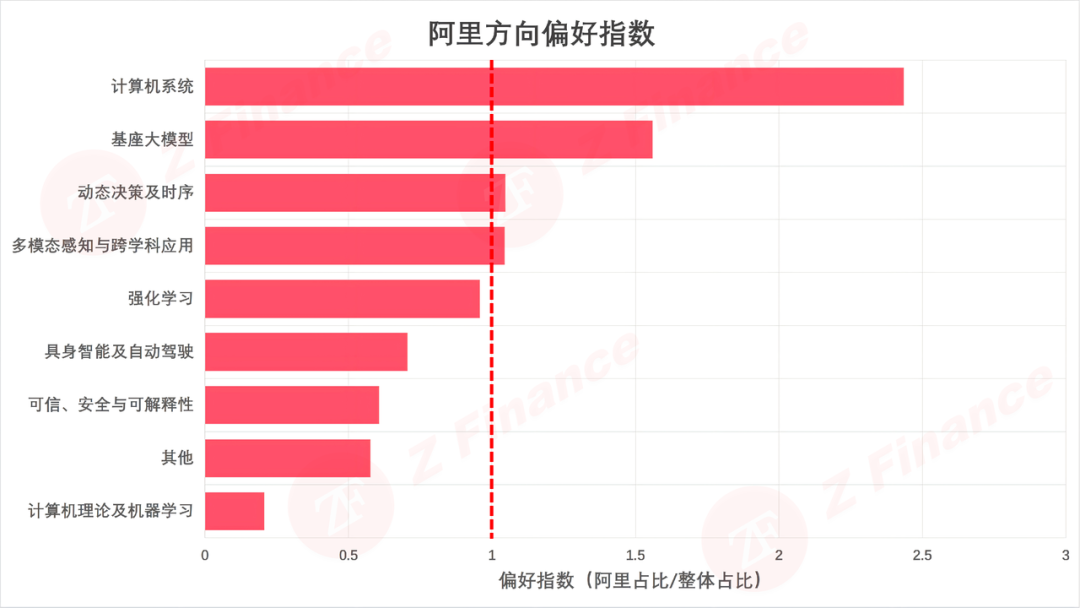
图 5 阿里方向偏好指数
如果说基座大模型是明牌,那计算机系统方向就是阿里的暗牌。表面上看,系统方向只有 5 篇论文,数量少得可怜。但别忘了,整个 ICLR 2026 在系统方向的占比仅 0.8%——阿里的偏好指数高达 2.44,重仓程度甚至超过基座大模型。
这透露了一个关键信号:当所有人都在卷模型能力,阿里已经开始死磕底层基础设施。毕竟,对于手握数万块 GPU 集群的云服务商来说,系统效率才是真正的护城河。
Oral 质量占比:与大盘持平,未见明显超车
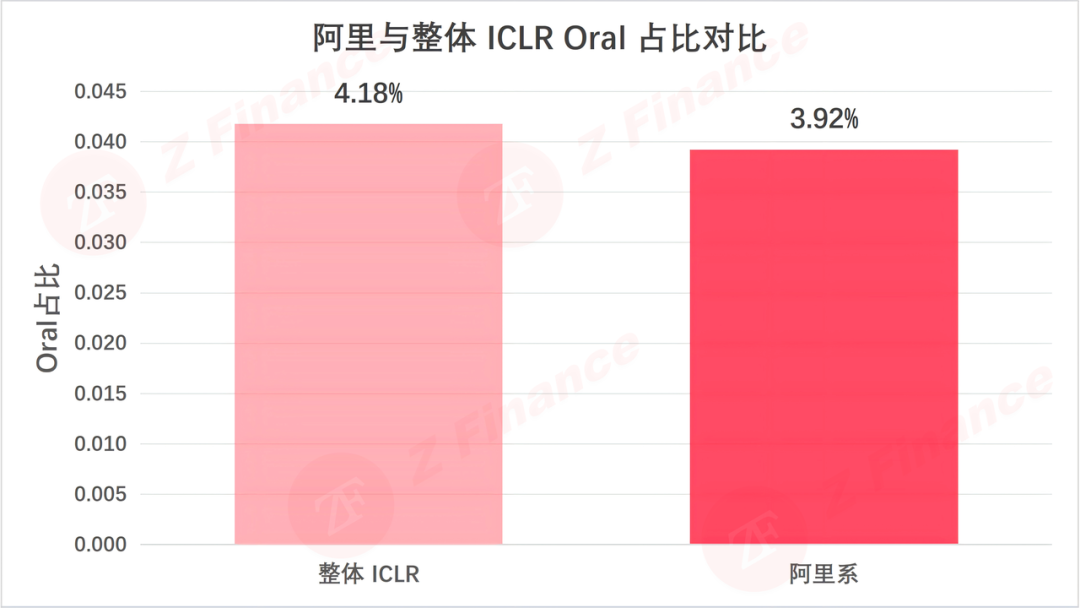
图 6 阿里与整体 ICLR Oral 占比对比
最后看一个硬核指标:Oral 占比。阿里系 Oral 论文 10 篇,占比 3.9%;ICLR 整体 Oral 占比 4.2%。-0.3 个百分点的差距,说明阿里在论文质量上稳住了基本盘,但并未形成显著的精品优势。
换句话说,相比顶级突破性成果,阿里更擅长规模化产出,把三个特征串起来看,阿里在 ICLR 2026 的打法已经非常清晰:
1.方向聚焦:基座大模型绝对重仓,多模态紧随其后,系统方向暗中发力
2.生态作战:96%的论文依赖外部合作,把自己变成产业研究平台
3.工程导向:偏好指数显示,阿里明显回避纯理论方向,全力押注工程可落地领域
这不是传统意义上的学术机构打法,而是平台型科技公司的典型策略——用产业资源换学术影响力,用合作网络换规模效应,最终目标不是顶会奖杯,而是 AI 基础设施的定义权。
注:
偏好指数 = 阿里在某方向的论文占比 / 整体 ICLR 在该方向的论文占比。偏好指数大于 1 表示阿里在该方向相对超配,小于 1 表示相对低配。
占比差值 = 阿里在某方向的论文占比 - 整体 ICLR 在该方向的论文占比,用于直观看结构差异。
本文新增的这些指标都属于描述性统计,用于说明方向结构,不做显著性检验。
10篇 Oral 看阿里系 ICLR 2026 的真正重心
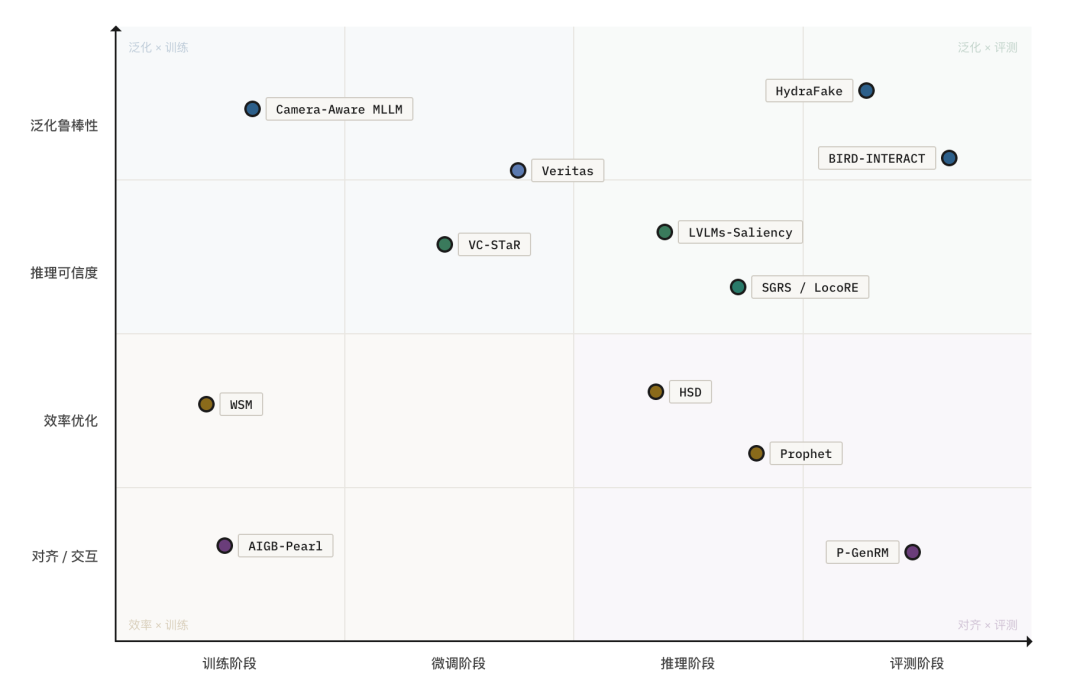
我们聚焦在阿里系在 ICLR 上的 10 篇Oral文章,相关研究大致沿着泛化性、推理可靠性、计算效率以及对齐与交互能力四条主线展开,并逐步形成了从数据构建、模型设计、先验注入、推理增强到评测范式重构的多层次研究图景。
首先,在泛化能力方面,现有工作已不再满足于封闭分布下的性能提升,而是更加关注模型在未见伪造类型、跨域场景以及复杂真实环境中的鲁棒性。一类研究从数据与基准构建入手,试图通过更贴近实际应用条件的训练与评测设置缩小实验环境与工业场景之间的差距。例如,HydraFake 强调多样化伪造技术、真实世界 forgery 以及严格的 out-of-domain 协议,从数据层面推动深伪检测研究由“同分布识别”转向“面向开放场景的泛化检测”;另一类工作从模型机制本身出发增强泛化能力。以 Camera-Aware MLLM 为代表的研究指出,仅依赖 RGB 输入的空间智能建模容易将几何属性与相机成像条件混合编码,导致模型过拟合于训练相机分布,因此有必要将相机内参显式纳入视觉 token 的条件建模之中,并辅以相机感知的数据增强策略与几何先验蒸馏,以提升跨相机条件下的空间推理能力。
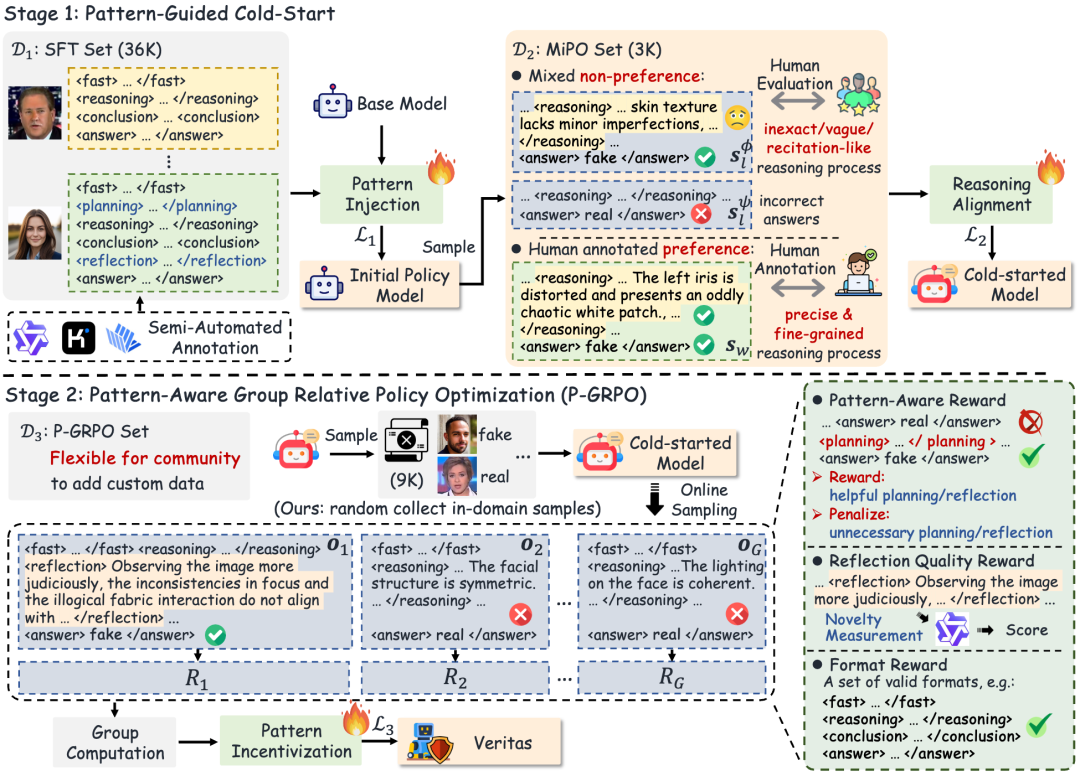
在推理能力与可靠性方面,一条重要方向是通过结构化推理机制增强模型的中间决策质量。Veritas 通过在传统 chain-of-thought 之外引入 planning 与 self-reflection 等关键模式,使模型能够以更接近人工鉴伪流程的方式逐步分析伪造线索;VC-STaR 从视觉对比的角度出发,利用对比式 VQA 样本帮助模型更准确地定位判别性视觉证据,并在此基础上生成质量更高、幻觉更少的视觉推理路径,进而实现视觉推理能力的自我提升。
VERITAS
在效率与优化方面,相关研究主要覆盖训练阶段与推理阶段两个层面。训练阶段的工作更多关注如何在不牺牲最终性能的前提下降低传统优化范式中的冗余设计。WSM 即代表了一类重新审视学习率衰减机制的研究,其核心观点在于通过 checkpoint merging 建立学习率调度与模型平均之间的形式联系,从而以一种 decay-free 的方式近似或替代常见的 cosine decay、linear decay 等退火策略。该类方法的意义不仅在于优化效率本身,也在于其为长期预训练和后续监督微调提供了更统一的训练动力学解释。
在对齐、交互与决策能力方面,研究关注点则进一步扩展至模型如何在开放环境中适应用户偏好、完成动态任务并实现可扩展的行为优化。P-GenRM 代表了个性化对齐方向的重要进展,其通过将用户偏好表征为结构化评价链,并在测试阶段引入基于个体与原型的双粒度缩放机制,使奖励模型不仅能够适配特定用户的细粒度偏好,还能借助相似用户群体的原型知识增强对新用户的泛化能力。
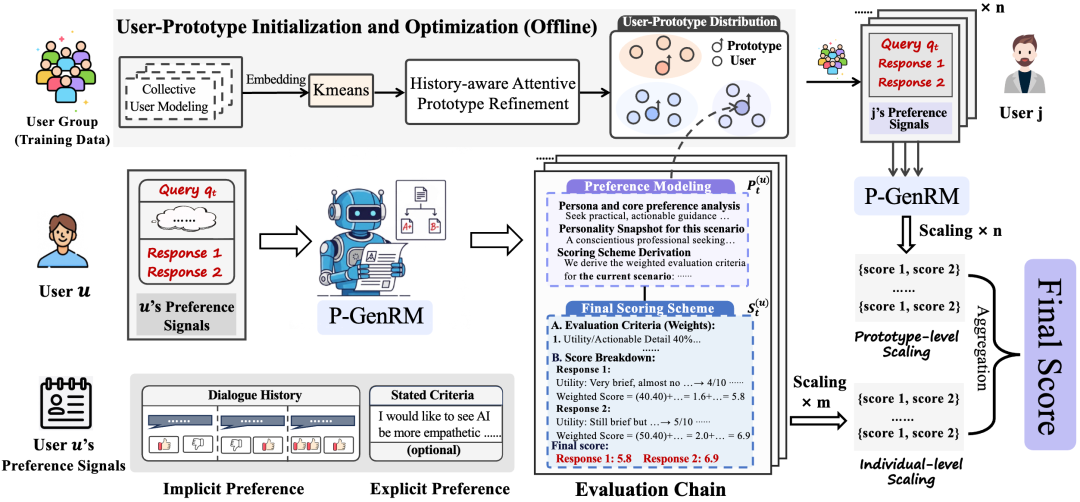
P-GenRM
综合来看,一方面,研究者通过更真实的数据分布、动态交互环境和更严格的评测协议不断暴露现有模型在开放世界中的能力缺口;另一方面,又通过结构化推理、先验知识注入、训练与解码机制优化以及个性化对齐等方法,系统性地弥补模型在泛化性、可靠性、效率和实用性上的不足。
作者: Cheng Gao, Shi Yuchen, Wang Shijie
*排名不分先后,按照首字母排序
Ref.
https://arxiv.org/pdf/2602.12116
https://arxiv.org/pdf/2508.21048
https://papercopilot.com/statistics/iclr-statistics/
数据来自 openreview 公开信息

稿件经采用可获邀进入Z Finance内部社群,优秀者将成为签约作者,00后更有机会成为Z Finance的早期共创成员。