95% vs 34%成功率、能耗降低近100倍:神经符号方法击败VLA模型

专属客服号

微信订阅号
大数据治理
全面提升数据价值
赋能业务提质增效
将 ScienceAI 设为星标
第一时间掌握
新鲜的 AI for Science 资讯


编辑丨%
过去两年,具身智能(embodied AI)走向一个明确方向:把视觉、语言和行动统一进一个大模型。这类模型被称为 Vision-Language-Action(VLA)模型——它们可以看、能听懂指令,还能直接输出动作。
但机器人学界正狂热地追逐越大越好的 VLA 大模型的同时,一个根本性的问题却被悄悄搁置:这些动辄数十亿参数、需要数天微调、运行时还要烧 GPU 的庞然大物,真的适合那些有明确规则和约束的结构化任务吗?
塔夫茨大学(Tufts University)的一支团队给出了一个响亮的否定答案。研究团队设计了一场「汉诺塔」操纵任务的公平对决:一方是当前最先进的开源 VLA 模型 π0,另一方则是一个结合了 PDDL 符号规划与扩散策略的神经符号架构(NSM)。
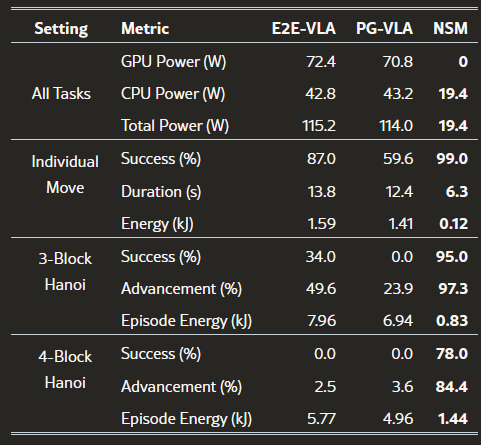
结果令人震惊——在 3 块汉诺塔任务上,NSM 成功率高达 95%,而 VLA 仅 34%;在面对未训练过的 4 块版本时,VLA 全军覆没,NSM 仍能达到 78% 的成功率。更讽刺的是,VLA 微调消耗的能量是 NSM 训练的近 100 倍。
相关的研究以「The Price Is Not Right: Neuro-Symbolic Methods Outperform VLAs on Structured Long-Horizon Manipulation Tasks with Significantly Lower Energy Consumption」为题,将于 5 月在维也纳国际机器人与自动化会议上发表,并发表于会议论文集。

论文链接:https://arxiv.org/abs/2602.19260
端到端 vs 神经符号
前文中所述的塔汉诺问题(Towers of Hanoi)是一款经典问题,这个任务具备三个关键特征:明确的规则约束 、长时间规划(long-horizon) 与强结构依赖,正是检验「推理能力」的理想场景。
在这任务中,π0 等模型在抓取、摆放等短程操作上虽然表现出色,但当任务需要多步推理、遵守特定规则(如汉诺塔的「大不能压小」)时,问题就暴露了——VLA 需要从演示中隐式地学习这些约束,而训练数据中任何细微的偏差或多样性都可能让模型无所适从。
而 NSM 则采用「分层」设计。高层用PDDL符号规划器,基于从少量演示中提取的抽象规则生成符号化计划;低层用扩散策略将计划转化为连续控制动作。这种设计将「推理」与「执行」解耦,规则清晰、可解释性强。
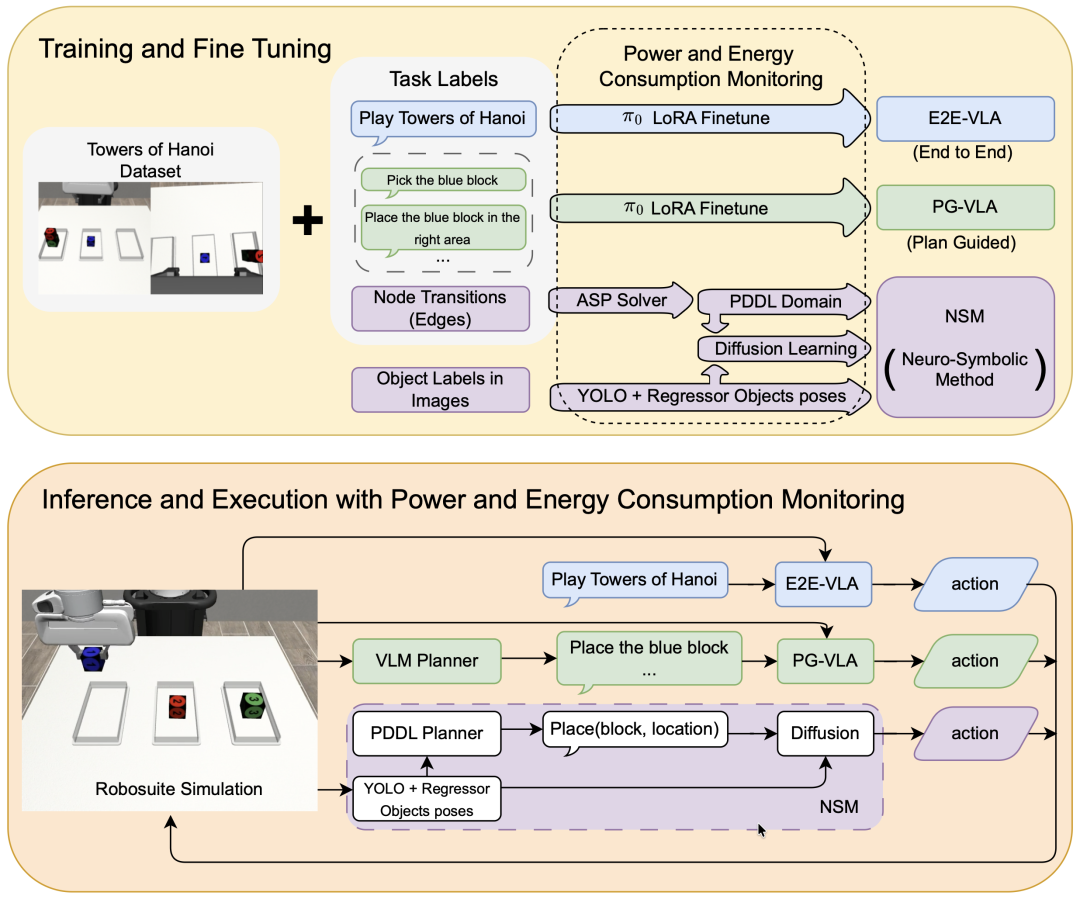
图 1:VLA 模型与 NSM 实验比较概述。
研究团队在 Robosuite 仿真环境中设计了三个难度递增的任务:单次抓取放置、3 块汉诺塔、4 块汉诺塔(后两者未见训练)。对比对象包括:
E2E-VLA:端到端微调,仅接收「玩汉诺塔」这一条高层指令。
PG-VLA:在外部规划器提供的最优子任务序列指导下微调,以隔离执行能力。
NSM:仅从50个简单的「堆叠」演示中学习,从未见过完整的汉诺塔求解过程。

图 2:数据集中的示例观测数据。
训练数据上,VLA 消耗了 300 个完整汉诺塔轨迹,而 NSM 只用了 50 个堆叠演示。硬件上所有实验在同一台 RTX 4090 上完成,并精确记录了 GPU/CPU 的功耗和能量消耗。
碾压性的结果差距
在最基础的三块塔汉诺任务中:
神经符号模型成功率:95%
最优VLA模型成功率:34%
差距接近 3 倍。
当任务稍微增加复杂度(4块)时:
神经符号模型仍能完成任务:78% 成功率
所有VLA模型:完全失败
表 1: 训练硬件指标,比较 VLA LoRA 微调与 NSM 训练。
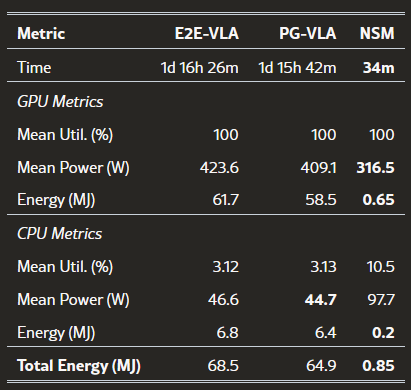
这意味着 VLA 不仅性能较低,而且几乎没有结构泛化能力。但这并非是结束,更关键的差距还在二者的能耗对比上。在训练阶段,VLA 微调能耗要高出神经符号方法近两个数量级(≈100倍)。即使是推理阶段,能耗也有接近 10 倍的差距。
VLA 的失败主因并非规划错误,而是低级执行上的偏差——反复抓取失败、放置位置不准。训练数据中的随机扰动(块位置偏移1cm)本意是增强稳健性,反而让模型难以锁定精确目标。在某些极端情况下,同一子任务指令的演示若区别较大,则很有可能出现对模型的强烈干扰,并进一步带来极高的失败率。
表 2:实验的功耗、能耗及任务表现。
能源风险与未来方向
研究团队将神经符号系统与熟悉的大型语言模型如 ChatGPT 或 Gemini 进行了类比。后者只是试图预测序列中的下一个词或动作,但这并不完美,可能导致结果失真或者出现错误的信息。而且,它们的能源消耗往往与任务本身不成比例。
VLA 或许更适合开放环境下的短程、灵活操作,而工业装配、实验室自动化、规则明确的物流任务,神经符号架构可能是更务实的选择。大规模部署时,能耗固然是一个不容小觑的问题。正如论文所言,「通用」不一定意味着更合算。

