为什么大模型难以直接做科学发现?MOOSE-Star:打破组合复杂度壁垒,解锁直接训练范式

专属客服号

微信订阅号
大数据治理
全面提升数据价值
赋能业务提质增效
将 ScienceAI 设为星标
第一时间掌握
新鲜的 AI for Science 资讯


在目前的 LLM for scientific discovery 研究中,绝大多数工作要么依赖于大模型推理期的 Prompting,要么基于 external feedback(外部实验 / 评委反馈)进行 training。
这引出了一个极其核心的拷问:为什么一直没人去「直接训练」并显式建模科学发现的生成过程 P (hypothesis | background) 本身?
最近一项工作首次从理论上揭示了其背后的死锁,提出了一套通用的科学发现理论框架,并成功观察到了令人振奋的 both Train-time Scaling Law 和 Test-Time Scaling Law。
该研究来自 MiroMind AI 的杨宗霖 (Zonglin Yang) 与邴立东 (Lidong Bing) 团队。为了推动直接训练范式在科学发现 (Scientific Discovery) 领域的应用,团队开发并开源了包含超 10.8 万篇高质量论文推导链路的 TOMATO-Star 数据套件 ,以及基于理论框架构建的 MOOSE-Star 模型体系。团队希望以此为契机,携手推动 Scientific Discovery 领域开源社区的建设与发展。

📄 论文地址:https://arxiv.org/pdf/2603.03756
💻 GitHub 数据与代码:https://github.com/ZonglinY/MOOSE-Star
🤗 Hugging Face:https://huggingface.co/papers/2603.03756
1. 核心壁垒:计算上几乎无解的 O (N^k) 组合复杂度
如果要直接训练模型生成科学发现,最大的挑战在于「灵感的检索与组合」。科学发现并非凭空产生,它要求模型从海量的全局文献库(规模为 N)中,精准检索出 k 个相关的灵感碎片,并将它们拼图般组合成一个新的 Hypothesis。
如果直接端到端让模型去隐式学习这个过程,其搜索空间是一个极其恐怖的组合爆炸:O (N^k)。
这种计算上几乎无解的复杂性,导致以往直接训练模型极易陷入死锁,表现为严重的幻觉或逻辑断裂。
2. 破局与统一理论:MOOSE-Star 的解构与分离范式
为了 enable 真正 tractable 与 scalable 的 discovery LLM training,MOOSE-Star 并没有去头铁地直接端到端训练 P (hypothesis | background)。
相反,该研究从第一性原理出发,首先提出并形式化了一个统一的科学发现理论框架。团队认为,高度复杂的科学发现过程必须先在理论层面被彻底解耦。依据这一证明过的理论框架,该研究提出了三个方法。
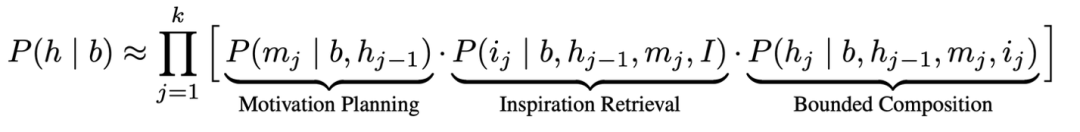
科学发现理论框架
方法一:IR 与 HC 的分离训练范式 (Decoupled Training)
这是保证整个框架「可训练 (Tractable)」的灵魂所在。根据该研究提出的科学发现理论,团队没有去直接硬训单一的 P (h|b),而是将训练过程解耦,分别独立训练灵感检索模型 (IR, Inspiration Retrieval) 和假设组合模型 (HC, Hypothesis Composition)。这种分离范式彻底避开了端到端建模复杂科学发现时的优化死锁,将复杂度从指数级 O (N^k) 降到了线性 O (k * N)。
方法二:动机引导的分层搜索 (Motivation-Guided Hierarchical Search)
该研究拒绝了在海量知识库中的全局暴力盲搜。模型首先基于背景知识,生成一个明确的「研究动机 (Motivation)」,然后顺着结构化的全局知识树进行分层、定向的检索。在最理想的情况下 (in the best case),这一机制成功将线性的复杂度 O (N) 降维至 O (log N)。
方法三:容错组合 (Bounded Composition)
在获取到检索结果后,模型在一个有界的上下文中,通过严密的生成式推理,将(即便带有一定噪声的)灵感碎片无缝融合成逻辑自洽的科学假设。
3. 核心发现:在科学发现领域解锁 Train-time 与 Test-Time Scaling Law
当该研究基于上述统一理论,成功打通了 tractable 的分离训练路径后,团队不仅解决了一个工程难题,更得到了一组非常惊艳的副产品 —— 在科学发现这一极其复杂的认知任务上,清晰地观察到了两条优美的扩展法则(Scaling Law)。
Train-time Scaling Law (训练期扩展法则):
过去,由于直接端到端拟合 P (h|b) 存在 O (N^k) 的复杂度之墙,此时「大力出奇迹」是失效的。
而 MOOSE-Star 的解构与分离训练彻底打破了这一魔咒。该研究证实:随着训练数据量(如 TOMATO-Star 数据集的规模扩张),模型在灵感检索和假设组合上的基础能力,呈现出了可预测的持续提升。这意味着,用 LLM 对科学发现进行直接建模 P (h|b) (不依赖 external feedback) 的能力首次变得「可以通过增加训练算力来 Scale up」。
Test-Time Scaling Law (推理期扩展法则):
除了训练期的规模化红利,MOOSE-Star 还在推理期展现出了惊人的算力转化率。
面对极其复杂的科学问题,传统的暴力采样(Brute-force)或盲目的 Prompting 会迅速撞上「复杂性高墙」,此时给予再多的推理算力(例如让模型盲猜 1000 次)也无济于事,成功率依然趋近于零。
而基于 MOOSE-Star 框架,得益于分层搜索与容错组合机制,随着该研究在推理期投入更多的计算资源(Compute,例如延展更深的逻辑搜索树、生成并评估更多的候选分支),模型产出高质量、创新性科学假设的成功率,呈现出极其稳定且持续的增长。
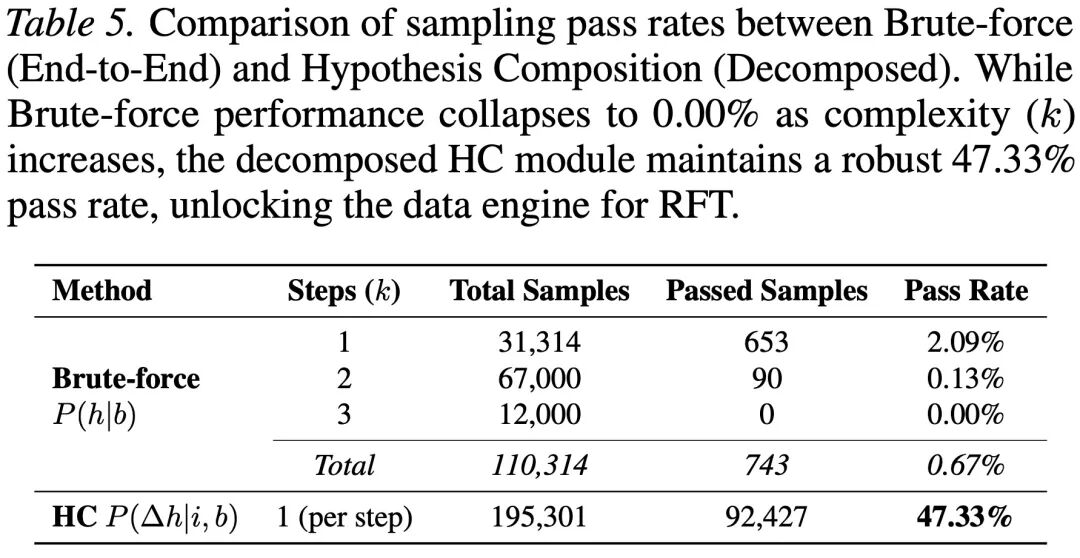
暴力 sampling 对 P (h|b) 失效
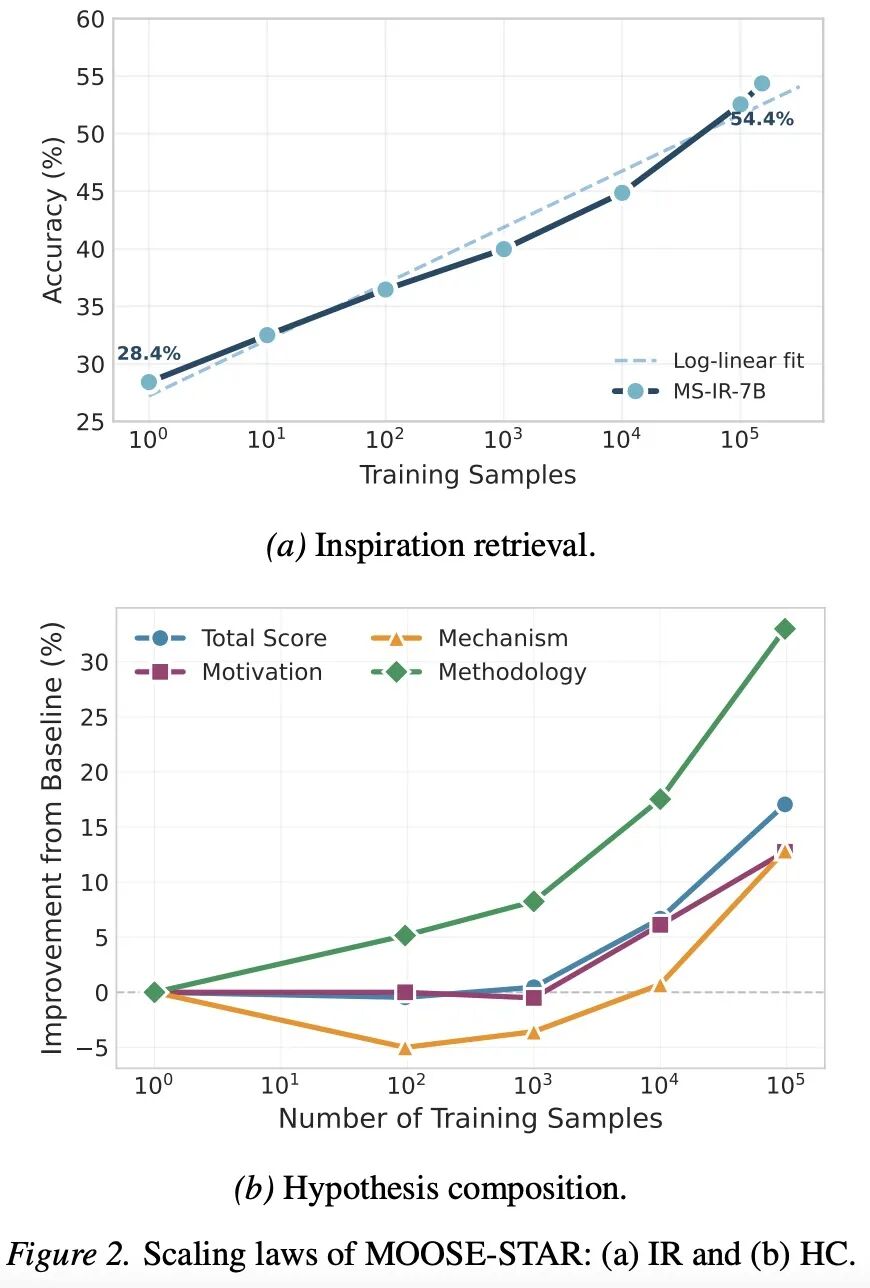
Train-time Scaling Law
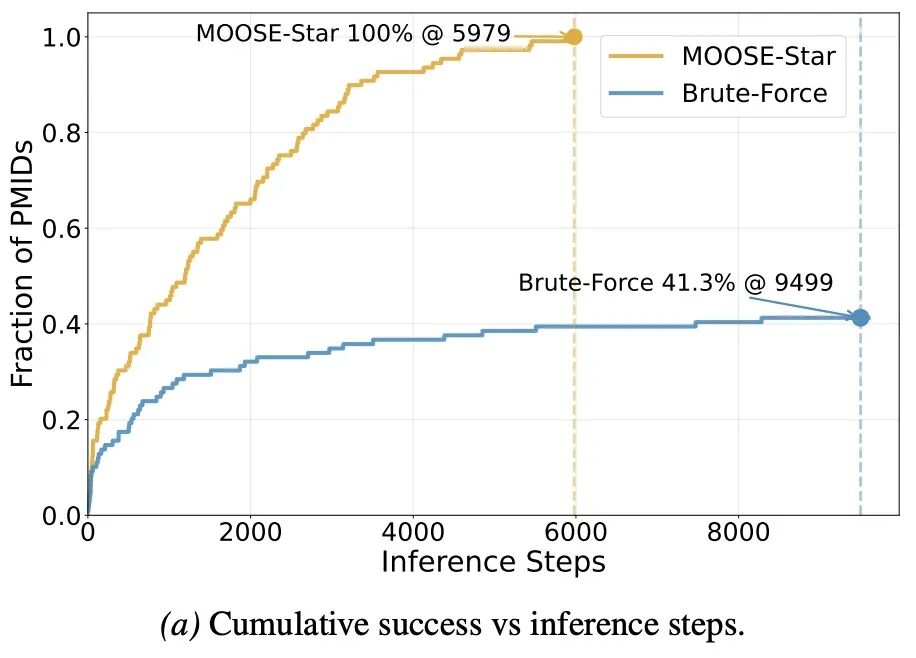
Test-time Scaling Law
4. 诚意开源:3.8 万卡时炼成的 TOMATO-Star 数据套件
为了支撑起这套庞大框架的验证与训练,数据是绕不过去的坎。
为此,该研究烧了约 38,400 个 A800 GPU 小时,对 108,717 篇近年来的高质量真实论文进行了极其精细的反向拆解,重构了从背景知识到科学假设的完整推导链路,构建了包含十万级样本的 TOMATO-Star 数据套件。
目前,这套十万级的数据集、完整的训练代码,以及微调后的系列模型已经全部开源!
团队非常期待这项工作能为整个 AI4Science 社区提供一个新的基座视角。如果大家对这个方向感兴趣,或者正在探索 LLM 的复杂推理机制,欢迎来 GitHub Repo 体验和交流!
人工智能 × [ 生物 神经科学 数学 物理 化学 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。

