最强Claude模型提前曝光!附带Anthropic三千份保密档案在线裸奔

专属客服号

微信订阅号
大数据治理
全面提升数据价值
赋能业务提质增效
抓马!向来标榜安全的Claude,竟然把自家模型泄露了!?
新模型代号
“Mythos”
,又叫
“Capybara(卡皮巴拉)”
,比当下Claude最强的Opus模型还大还强。

甚是离谱的是,这波曝光,甚至不是外部攻击,而是一次
权限配置失误
。
一篇Anthropic自家博客草稿,被错误设为公开,于是,这只“卡皮巴拉”就这么水灵灵地被全网围观了。
更让人绷不住的是,
CEO也没能逃过这场风波
,他的度假计划,也被这位马大哈员工公开到了网上??

(你说这事儿闹的...)
比Opus 4.6更夯的Claude Mythos
事情的起因,源于一场荒诞的技术性「手滑」。(doge)
几天前,Anthropic内部的内容管理系统(CMS)在进行版本迁移时,出现了一个致命的配置疏忽。
将一个存储公司核心资产的数据库权限,从内部私有错点成了完全公开,直接把内部机密资产的数据库权限直接「开盒」。
而且还是
完全没有加密
的那种,结果可想而知——大量图片、PDF和博客草案直接在互联网上《裸奔》。
好巧不巧,这个漏洞恰好被剑桥大学研究员和网络安全公司LayerX Security的在扫描过程中发现。
不看不知道,一看吓一跳,里的内容可以说是让研究人员直接倒吸一口凉气——
3000份
Anthropic内部保密未公开的资产档案,赫然呈现在眼前。(瞪大眼.jpg)

而其中的一篇保密
但没保密成功
的数据资料里,直接爆出了还在测试的秘密模型——
Claude Mythos
。
有网友在文章下架之前把A社的两篇博客草稿保存了下来,这两篇一篇管这个模型叫Mythos,另一篇则称之为Capybara,但除了名称之外,这两篇草稿的其他内容基本一样。

在泄露文件中,曾多次使用质的飞跃这种说法来形容Mythos,甚至据说比目前的
最强模型
Opus
更大且更智能
。
没有概念没关系,人家资料里直接拿对比说话了:
在具体能力上,相较于Claude Opus 4.6,Mythos在软件编码、学术推理和网络安全等测试中的得分显著更高。
不仅如此,泄漏文件中还提到,目前Anthropic已完成了对于该模型的相关训练。
并且还说了这么一句话:
Claude Mythos,就是迄今为止公司开发过的最强大的AI模型!!!
嚯!比Opus4.6还强大的模型,何意味?
要知道,目前Claude主要有三款模型:分别是轻量级模型Haiku、中量级模型Sonnet,以及旗舰型模型Opus。
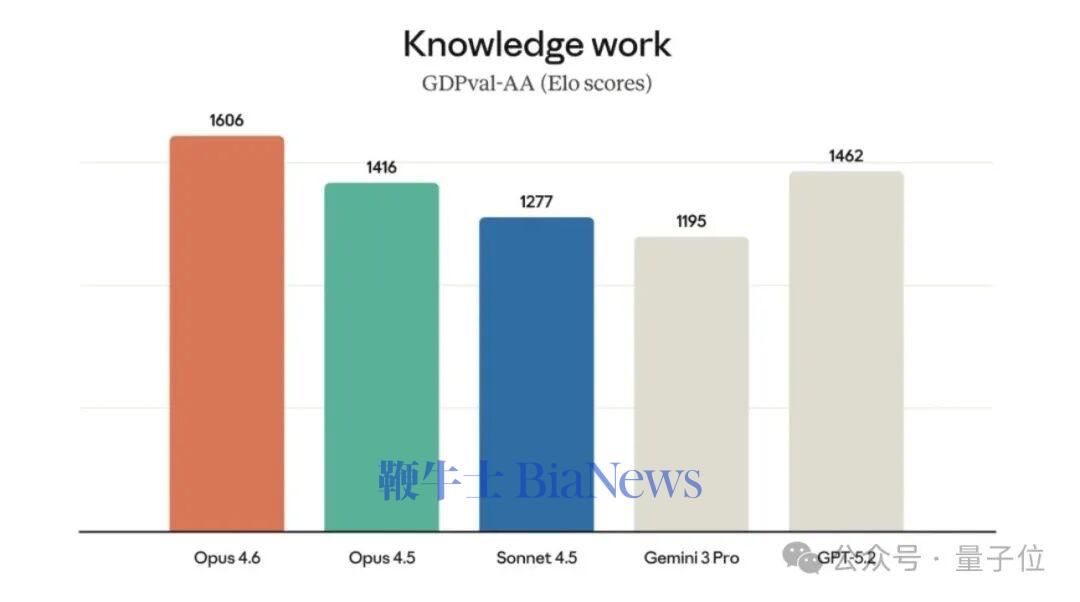
在具体表现上,不久前发布的Opus 4.6,在复杂长文本处理和推理能力上已经处在当前模型第一梯队。
在GDPval-AA(一项评估金融、法律和其他领域经济价值知识工作任务的性能指标上),Opus 4.6比GPT-5.2高出144个
Elo
!!!
如果真要像文件里所说的,Mythos能比Opus 4.6还强。
那么,这事儿还真就不太好说了。
反正我估计隔壁OpenAI真得瑟瑟发抖了...
奥特曼:原本以为大家还在一个量级里切磋,谁知道人家私下搞这一套秘密玩法啊??
安全风险让A社自己都害怕
Anthropic承认,其内容管理系统配置中的“人为错误”导致草稿博客文章变得可访问。
按照A社的说法,这些材料属于“考虑发布的内容的早期草稿”,也就是说早晚会公开,但因为泄露被提前了。
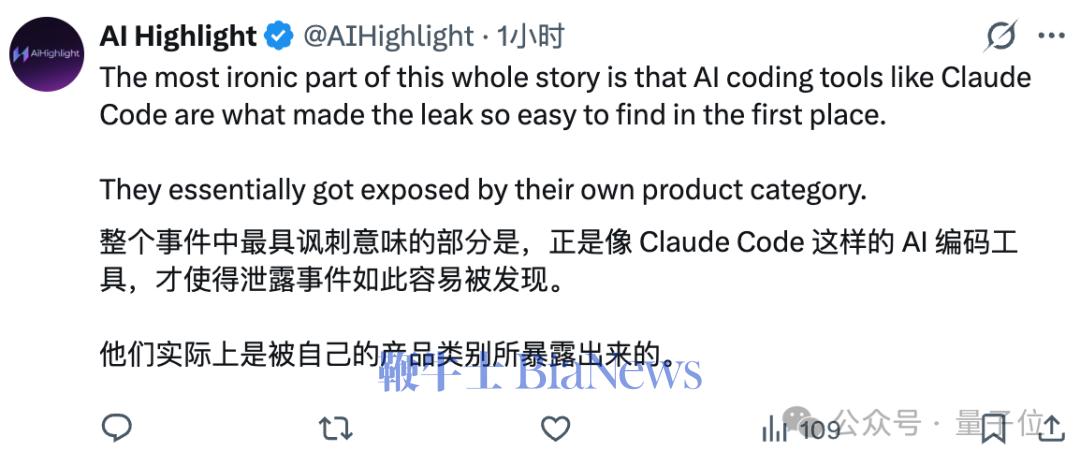
有网友锐评,因为有了Claude Code,导致被公开的文件更容易被发现,A社这波是被自己家的产品反噬了??
(有点太鲨人诛心了啊...)
事儿越闹越大,再不站出来说两句都不太好了。
人家A社发言人也承认了,他们确实正在训练和测试一款新模型。
我们正在开发一款通用模型,它在推理、编码和网络安全方面都有显著提升。
鉴于其强大的功能,我们正在谨慎地发布这款模型。按照行业惯例,我们正在与一小部分早期用户合作测试该模型。我们认为这款模型是一次飞跃,也是我们迄今为止构建的最强大的模型。
由于该模型在代码和网络安全领域的能力远超现有水平,甚至可能被用于发起大规模网络攻击,公司将其限制在极少数早期访问客户范围内进行封闭测试。
这种分阶段披露的做法是为了给网络防御组织留出提前量,让他们能够利用模型的能力先行加固代码库,以应对未来可能出现的AI攻击。
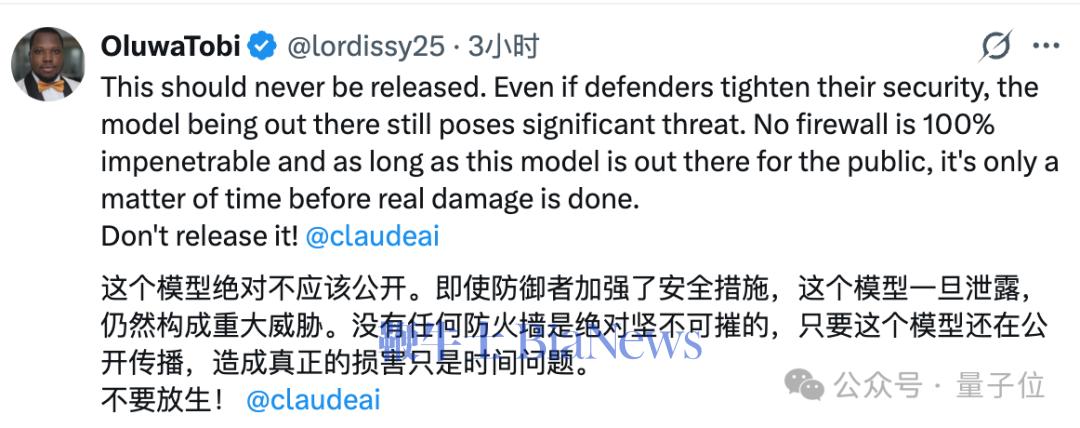
有人更是呼吁,这样的模型无论如何都不应该公开,因为根本不存在绝对坚固的防御系统。
其实,目前已经有的Opus 4.6,就已经具备了发现生产代码库中此前未知漏洞的能力。
A社已经承认,这项功能具有双重用途,这意味着它既可以帮助黑客,也可以帮助网络安全防御者发现并修复代码中的漏洞。
还有隔壁OpenAI,在发布GPT-5.3-Codex时,也称其是根据“网络安全准备框架”评定的首个“高能力”网络安全相关任务模型,也是首个直接训练用于识别软件漏洞的模型。
也就是说,不管Anthropic还是OpenAI,它们最新一代的前言模型,都已经破了某个门槛,将带来新的网络安全风险。
不过也有人认为,泄露的信息并不等于100%的事实,无法排除炒作成分,所以还是拭目以待最终交付的产品究竟如何。

(转载自量子位)

